Overview
- Key Insights On Context Rot
- 实际任务中的语义理解挑战
- 实验一: NIAH 扩展实验
- 实验二: LongMemEval 对话问答实验
- 实验三: Repeated Words 重复词语任务
Recap: NIAH 大海捞针测试
- Needle in a Haystack (NIAH) 测试: 给定一个很长的文本输入,然后问个问题,问题的答案藏在长文中的某一句,然后回答问题看能不能根据答案找到回答, 也叫大海捞针测试,示例如下:
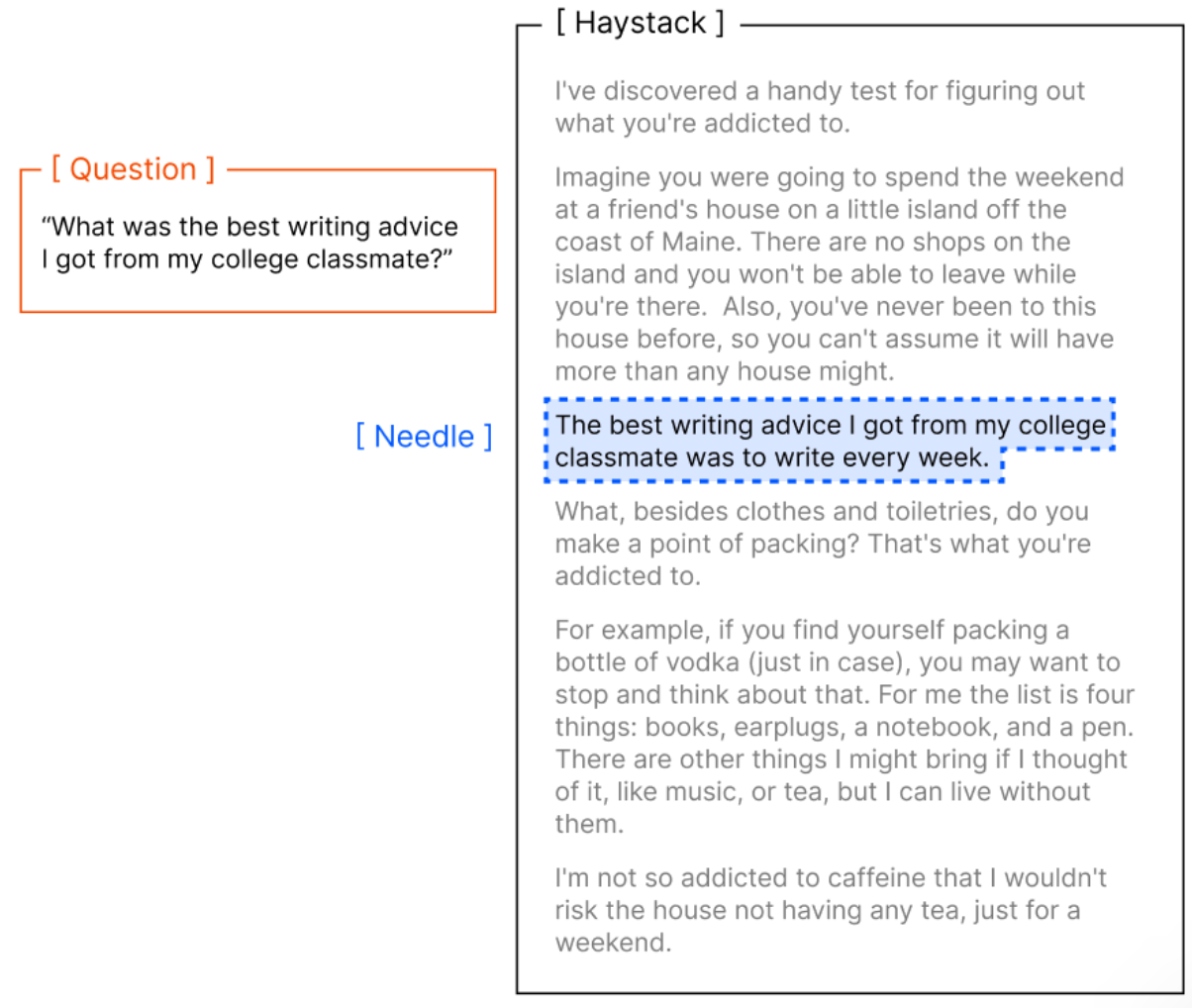
NIAH 任务的 Prompt 模板
你是一个智能助手,需要从长文本中找到目标信息。注意:信息可能没有直接字面匹配,需要推理和理解上下文关系。
任务:
1. 阅读下面的上下文(Context)。
2. 根据目标问题(Question)找到答案。
3. 不要输出无关信息或多余解释。
4. 输出格式:
Answer: <答案>
Context:
<这里填入长文本上下文>
Question:
<这里填入问题>
- NIAH 测试如果效果很好,在一定程度上说明 LLM 具备一定的长上下文处理能力
Key Insights On Context Rot
- 通常 LLM 我们认为能具备均匀处理上下文的能力, 也就是说: LLM 处理长度 100 token 的输入和处理长度 10000 token 长度的输入没区别, 验证这个结论的方法是找一些窗口长度很长且能力很强的模型做 NIAH 测试,测试结果发现是能处理的很好的
- 但其实 NIAH 基准不是一个完美的测试基准,因为这种测试偏向于一种 “词汇匹配检索”, 无法解决真实需求中的语义理解、歧义处理需求
- 输入长度拉长会导致 LLM 性能出现显著的、不均匀的下降, Context Rot 问题设计一些实验去说明
- 输入长度拉长会导致 LLM 性能出现显著的、不均匀的下降
- NIAH 扩展实验: 即使是 NIAH 任务, 在不同长度输入下,面对更复杂的语义理解要求, 引入干扰项或者改变文本结构,对结果影响也很大
实际任务中的语义理解挑战
NoLiMa: NIAH 不能有效衡量 模型在 “需要推理、需要理解隐含关联” 的长上下文环境下的能力, 因此 NoLiMa 设计长上下文检索/理解任务,尽量减少字面重合 (lexical overlap),要求模型从庞大且杂乱的上下文中,根据隐含的关联(latent association)而非字面匹配,找到目标信息。
举个实际任务中的语义理解挑战例子
Question: Which character has been to Helsinki?
问题:哪个角色去过赫尔辛基?
Needle: Actually, Yuki lives next to the Kiasma museum.
尼德尔:实际上,Yuki住在奇亚斯玛博物馆旁边。
这要求模型知道 “奇亚斯玛博物馆” 是在 “赫尔辛基” 这个地方的, 这种属于的是模型的 world knowledge (世界知识), 所以这种问题模型很难搞定
实验一: NIAH 扩展实验
NIAH 扩展实验引入 4 个变量,测试这个 4 个变量场景下,随着输入长度增加, NIAH 实验效果会怎么样 ?
- 变量1: Needle 和 Question 的相似度: 随着长度的增加,相似度越低的这部分,性能下降越快
- 变量2: 不光是有 Needle, 要给 doc 里面增加 1 个或者多个干扰项: 1 个 干扰项相比没有干扰项,就已经能让性能下降,引入 4 个干扰项,性能下降显著严重
- 变量3: Needle 和 Haystack 的相似度: 这个很难评估,至少证明了 Haystack 不是影响最大的因素
- 变量4: Haystack 结构的影响,打乱 Haystack 的结构,搞成随机重排 无逻辑内容,反而能让模型性能提升, 这太反直觉了; 推测原因: 输入结构会影响 LLM 注意力机制,连贯文本可能分散模型对 “针” 的关注,打乱文本减少这种干扰
实验二: LongMemEval 对话问答实验
LongMemEval 是个长上下文对话文达的基准, 给定 user 和 assistant 的聊天历史,模型的任务是回答一个与该聊天历史的某个部分相关的问题, 以下是一些设定
对话历史平均包含 11.3 万 token(约 8.5 万字),覆盖多轮对话(平均 35 轮),其中 70% 内容为无关信息(如闲聊、重复内容、上下文无关的问题),仅 30% 与最终问题直接相关。示例:用户与助手讨论旅行计划,中间穿插天气查询、餐厅推荐等无关话题,最终问题聚焦 “航班取消政策”。
Needle 信息分布:关键信息(”针”)被随机嵌入在对话历史的不同位置:
早期位置(前 20% 对话)
中期位置(中间 60% 对话)
晚期位置(后 20% 对话)
上下文输入类型有两种
- 完整输入:直接将 11.3 万 token 的完整对话历史作为输入,要求模型 “基于整个对话回答问题”。挑战:模型需先从海量无关信息中检索出相关内容,再进行推理。
- 聚焦输入:仅提供与问题直接相关的 300 token 内容(过滤掉所有无关对话),模拟 “精准上下文” 场景。基准:测试模型在理想情况下的推理能力,排除检索干扰。
问题类型覆盖
实验设计了 5 类问题,覆盖真实聊天中的常见需求:
| 问题类型 | 示例 |
|---|---|
| 事实提取 | “用户提到的航班号是多少?”(需从对话中定位具体数字) |
| 多轮推理 | “用户最终选择的酒店是否允许携带宠物?”(需整合多轮讨论的偏好变化) |
| 时间推理 | “用户原定的出发日期比实际提前了几天?”(需对比不同轮次的时间信息) |
| 知识更新 | “用户是否修改了会议地点?”(需识别最新对话中的信息覆盖旧信息) |
| 歧义处理 | “用户说的‘红色行李箱’是指托运箱还是登机箱?”(需结合上下文消歧) |
关键结论:
- 所有模型在 “聚焦输入” 下的准确率显著高于 “完整输入”,平均差距达25%-40%。GPT-4.1 在聚焦输入下准确率为 82%,完整输入降至 58%;
Claude Opus 4 在聚焦输入下准确率为 75%,完整输入降至 41% - 模型差异:
- Claude 系列:弃权率最高(完整输入下平均 35%),性能差距最明显(聚焦输入比完整输入高 34%);
- GPT 系列:幻觉率最高(完整输入下平均 28% 错误答案),但性能差距较小(聚焦输入比完整输入高 22%);
- Gemini 2.5 Pro:变异性最大,同一问题在完整输入下的准确率波动范围达 ±15%
- 输入长度的非线性影响
- 阈值效应:当对话历史超过 8 万 token时,模型性能开始加速下降。例如:在 8 万 token 时,Claude Sonnet 4 的准确率为 60%;在 11.3 万 token 时,准确率骤降至 38%。
- 位置敏感:关键信息越靠近对话历史的末尾,模型在完整输入下的准确率越低。例如:晚期位置的关键信息在完整输入下的识别率比早期位置低18%-25%。
- 模型差异的详细比较
- Claude 系列:保守主义的代价与收益
- 策略:优先选择 “弃权” 而非猜测,尤其在信息不明确时。
- 示例:当问题依赖多个分散的信息点时,Claude Sonnet 4 会回复 “需要更具体的上下文”。
- 优缺点:优点:幻觉率最低(完整输入下仅 9%),适合对准确性要求极高的场景(如法律文书处理);缺点:弃权率高,在开放域对话中可能显得 “不够智能”。
- GPT 系列:自信的风险
- 策略:倾向于生成完整回答,即使信息不充分。
- 示例:在用户未明确说明酒店位置时,GPT-4.1 可能虚构 “位于市中心商业区”。
- 优缺点:
- 优点:在聚焦输入下表现最佳(准确率 82%),适合需要快速响应的场景(如客服);
- 缺点:完整输入下幻觉率高,可能导致严重误导。
- Gemini 与 Qwen:创新与不稳定并存
- Gemini 2.5 Pro:
- 特点:在长输入下可能生成 “创造性” 回答,例如将用户提到的 “红色行李箱” 联想为 “品牌限量款”;
- 风险:变异性大,同一问题的回答质量波动显著。
- Qwen3-8B:
- 特点:在完整输入下有时会生成无关内容(如突然讨论 “海滩度假”);
- 优势:聚焦输入下表现稳定,适合中文场景(如多轮电商咨询)。
- Claude 系列:保守主义的代价与收益
一些认知启发:
- 打破长上下文能力的 “完美幻觉”, LongMemEval 实验揭示了一个残酷现实:即使是最先进的 LLM,也无法在长对话中保持稳定的高性能。模型的表现不仅取决于上下文窗口大小,更受输入结构、信息分布和任务类型的深刻影响。未来的突破点将不仅在于扩大窗口,更需在上下文管理(如智能摘要、动态检索)和模型鲁棒性(如降低幻觉、优化弃权策略)上取得进展。对于开发者而言,理解这些实验结论是设计可靠 AI 系统的关键 —— 长上下文不是 “容量竞赛”,而是 “精准使用” 的艺术。
- 对业界的警示: 现有基准的局限性:传统 NIAH 基准仅测试 “词汇匹配”,而 LongMemEval 证明,即使模型在 NIAH 中表现优异,也可能在真实对话中因 “语义理解 + 长序列处理” 双重挑战而失效。上下文工程的必要性:直接投喂完整对话并非最优解,需通过摘要生成、关键信息高亮等技术优化输入结构。
- 对应用开发的指导
- 场景适配:高风险场景(如医疗、金融):优先使用 Claude 系列,接受较低响应速度以换取高可靠性;效率优先场景(如信息查询):可选择 GPT 系列,但需搭配外部验证机制。
- 输入优化策略:
- 将关键信息置于对话开头;
- 定期对长对话进行语义压缩(如每 5 轮生成摘要);
- 明确区分 “需记忆内容” 与 “临时信息”。
- 未来研究方向
- 注意力机制改进:探索如何让模型更关注对话历史中的 “关键转折点”(如用户语气变化);
- 外部记忆增强:结合向量数据库(如 Chroma 自身产品)实现动态检索,缓解 LLM 内部记忆的局限性;
- 评估标准革新:将 “弃权率” 和 “幻觉率” 纳入核心指标,避免模型为追求准确率而牺牲可靠性。
实验三: Repeated Words 重复词语任务
Repeated Words 重复词语任务设计: 模型输入是个很长的序列,然后只需要让模型原封不动输出这个序列, 输入序列构成: 一堆重复常见词和一个特殊词,特殊词随机插入到这一堆重复的常见词里面, 例如常见词我们用 apple, 重复词我们用 apples, 写个 prompt 如下:
Simply replicate the following text, output the exact same text: apple apple apple apple <apples> apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple
然后改变输入的长度:
- Number of words: 25, 50, 75, 100, 250, 500, 750, 1000, 2500, 5000, 7500, 10000
- 独特词的位置:开头,结尾,偏后面的位置
考察标准:
- 精确复制率: 完全一致的占比
- 独特词识别准确率: 其他的可以错,独特词正确复制了就算对
- 错误类型的分布: 漏了词,独特词替换, 无意义生成等
intuitively,
- 这个任务乍一看很简单,我第一次看的时候感觉这还能出错吗 ? 实验发现真的能出错
- 为什么这么设计? 没有任何的语义难度和推理难度全部降为 0, 通过固定任务只改变喂一词的位置这一个极简任务, 单纯考察模型对长上下文的依赖能力
实验结果
- 实验表明,模型性能随输入长度增加呈现非线性下降趋势:
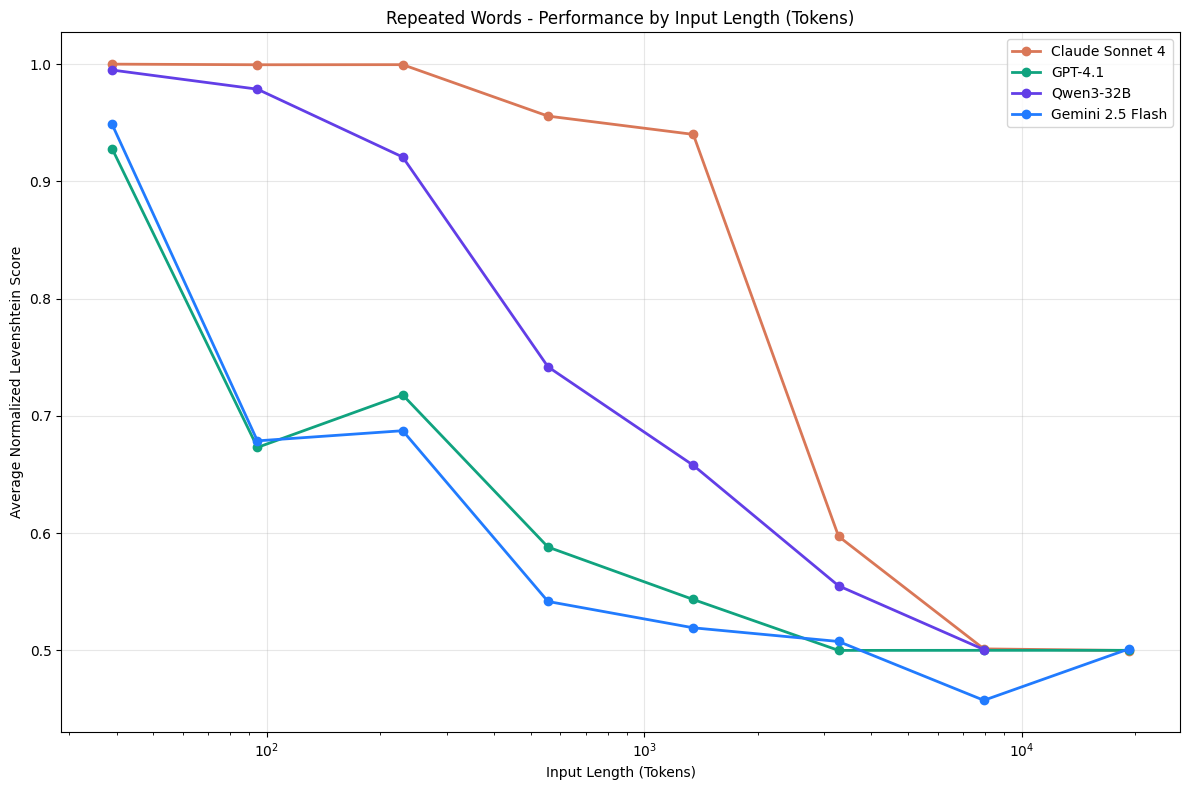
- 独特词在序列中的位置显著影响模型表现:
开头位置:准确率最高(85%-90%),因模型对序列起始部分的注意力分配更集中。
中间位置:准确率降至 60%-70%,需平衡前后文信息的记忆压力。
结尾位置:准确率最低(40%-50%),模型因需完整记忆长序列导致 “尾部遗忘”。
这种位置敏感性反映了 Transformer 架构对序列时序信息编码的非均匀性,即越靠近末尾的 token 越容易被稀释
Reference
[1]. Context Rot: How Increasing Input Tokens Impacts LLM Performance.
转载请注明来源 goldandrabbit.github.io