Overview
1.针对 LLM 在数学推理模型, 讨论了在 Supervised LLM 设定下数学推理模型 accuracy 的相关影响因素
2.提出 Rejection sampling Fine-tuning (RFT) 中最关键的思路是增大差异化的推理路径数量
the key factor influences fine-tuning on rejection sampling (RFT) augmented data is distinct reasoning path amount
RFT 的思想和细节
Rejection sampling Fine-Tuning, 拒绝采样微调分为 3 步骤
(i). 利用 SFT 模型生成候选
(ii). 通过某种筛选机制, (人工评审或者自动评分系统), 筛选高质量样本
(iii). 利用筛选的高质量样本微调
exhuasively,
1.对于本文研究的数学推理问题, 已有 SFT model $\pi$, 对于每个 $q_i$, 产出 $k$ 个 candidates reasoning path $r$ 和 answer $a$, 过滤掉错误答案

2.针对 $k$ 的选择问题, 实验对比了 {1,3,12,25,50,100}, 其中 $k=100$ 不过滤任何 reasoning path 记录为 no dedup (不去重), 结果如下
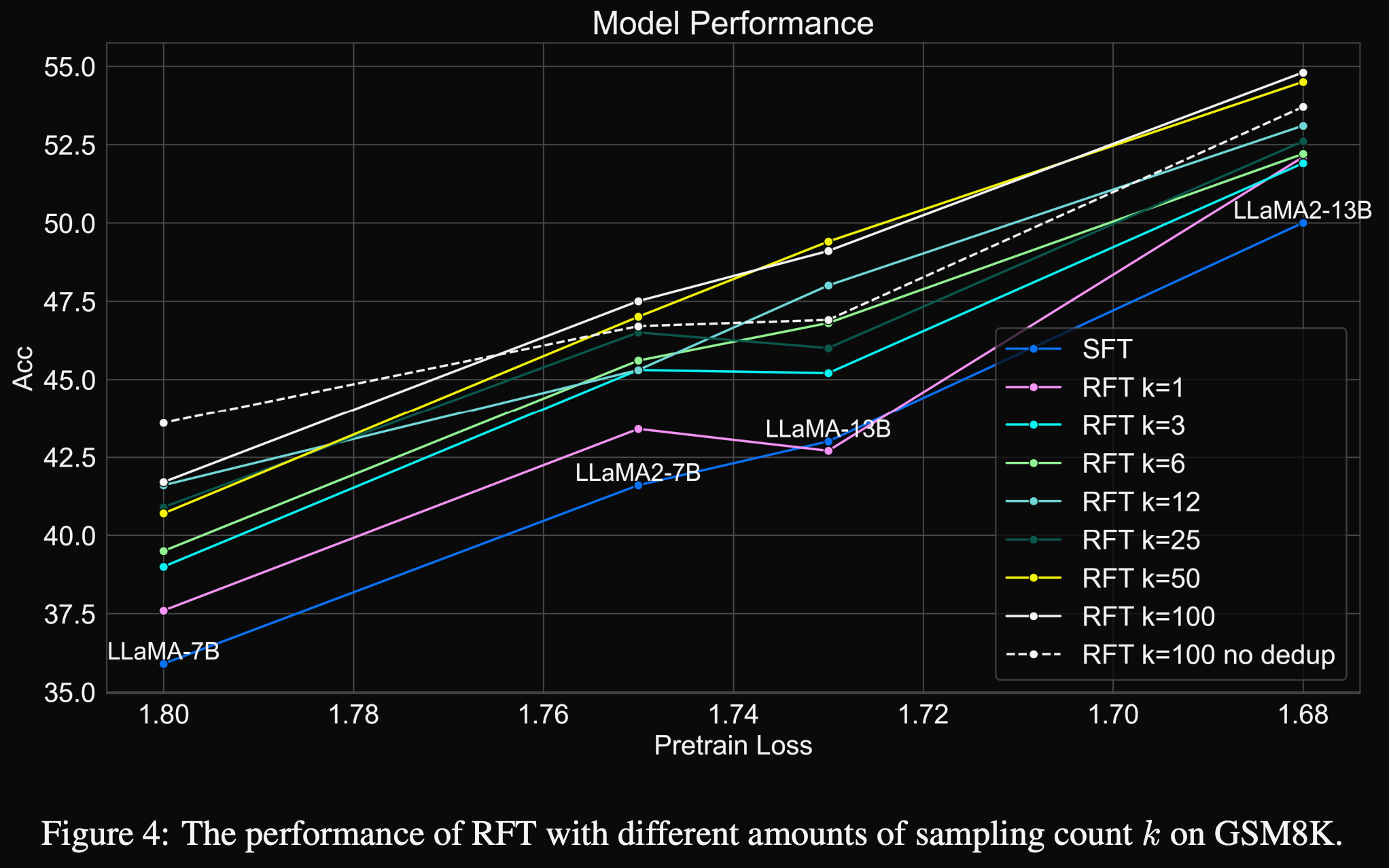
3.比较 $k=100$ 和 no dedup 结果差不多, 说明其实有差异的 reasoning path 的数量决定了模型效果, 而不是样本数量
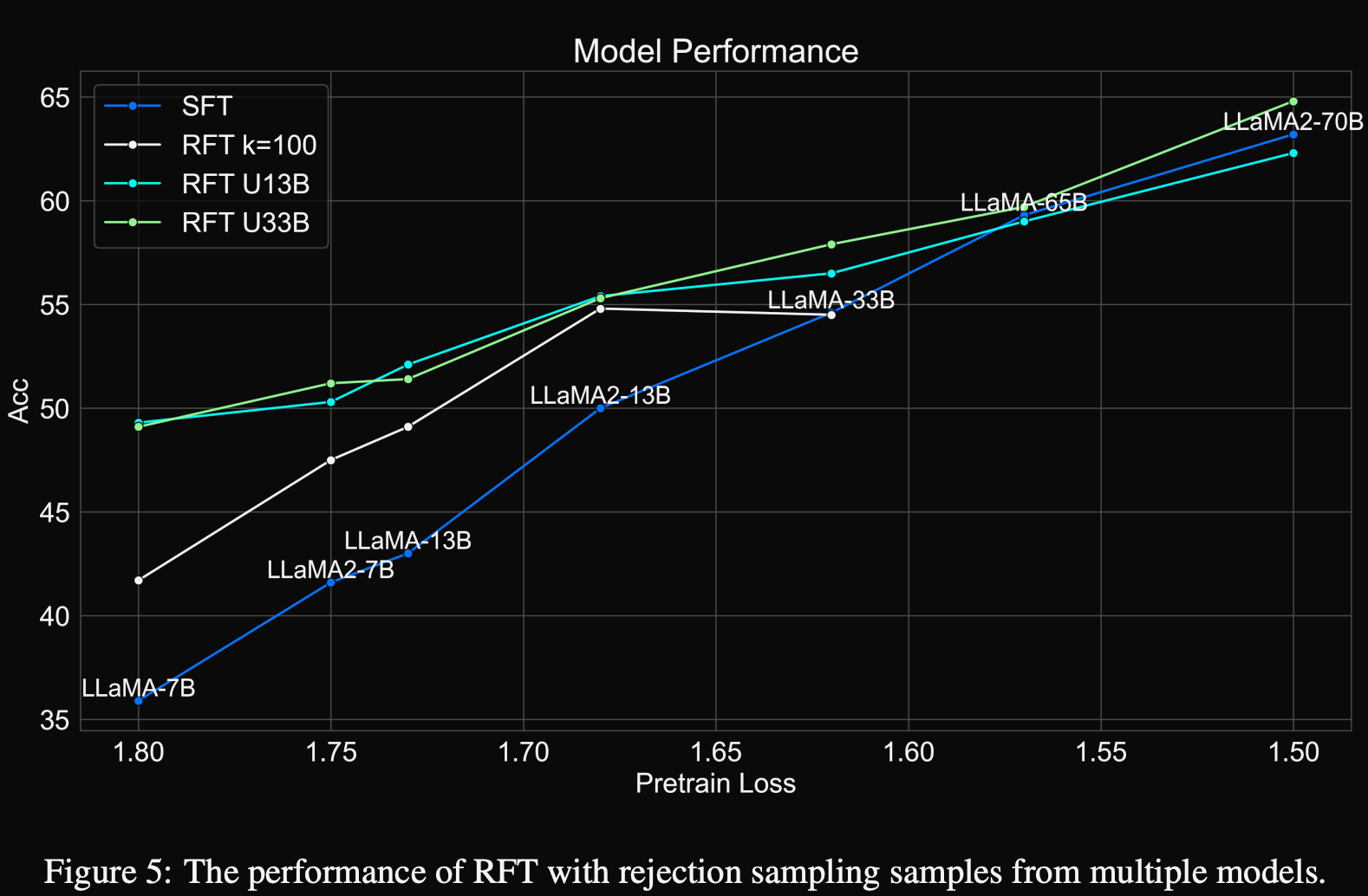
the reasoning paths sampled from one single SFT model can be logically non-diverse. Therefore, we expect to further improve the mathematical reasoning performance by leveraging rejection sampled reasoning paths aggregated from different models.
4.从单个 SFT model 采样还是不够 diverse, 所以用多个 SFT 模型做 rejection sampling, 最简单的是做不同 B 参数下的合并
这里
(i). 7B/13B/33B means LLaMA-7B/13B/33B, 7B2/13B2 means LLaMA2-7B/13B
(ii). $\oplus$ 表示个聚合过程, 将来自不同集合的所有 reasoning paths 进行整合,随后通过 Algorithm 1 对具有相同方程形式与计算顺序 equation forms and orders 的推理路径进行去重, 若两个推理路径分别生成:
x+3=5⇒x=5-3⇒x=2
5=x+3⇒5-3=x⇒x=2
通过聚合算法 Algorithm 1 进行去重
Reference
[1]. Scaling Relationship on Learning Mathematical Reasoning with Large Language Models. https://arxiv.org/pdf/2308.01825.
转载请注明来源 goldandrabbit.github.io