Self-Rag 核心思想
Self-RAG 实现像人查资料一样的检索+判断的流程 ,先判断 “要不要查” => 再筛 “资料有用没” => 最后 “用资料答且验证”
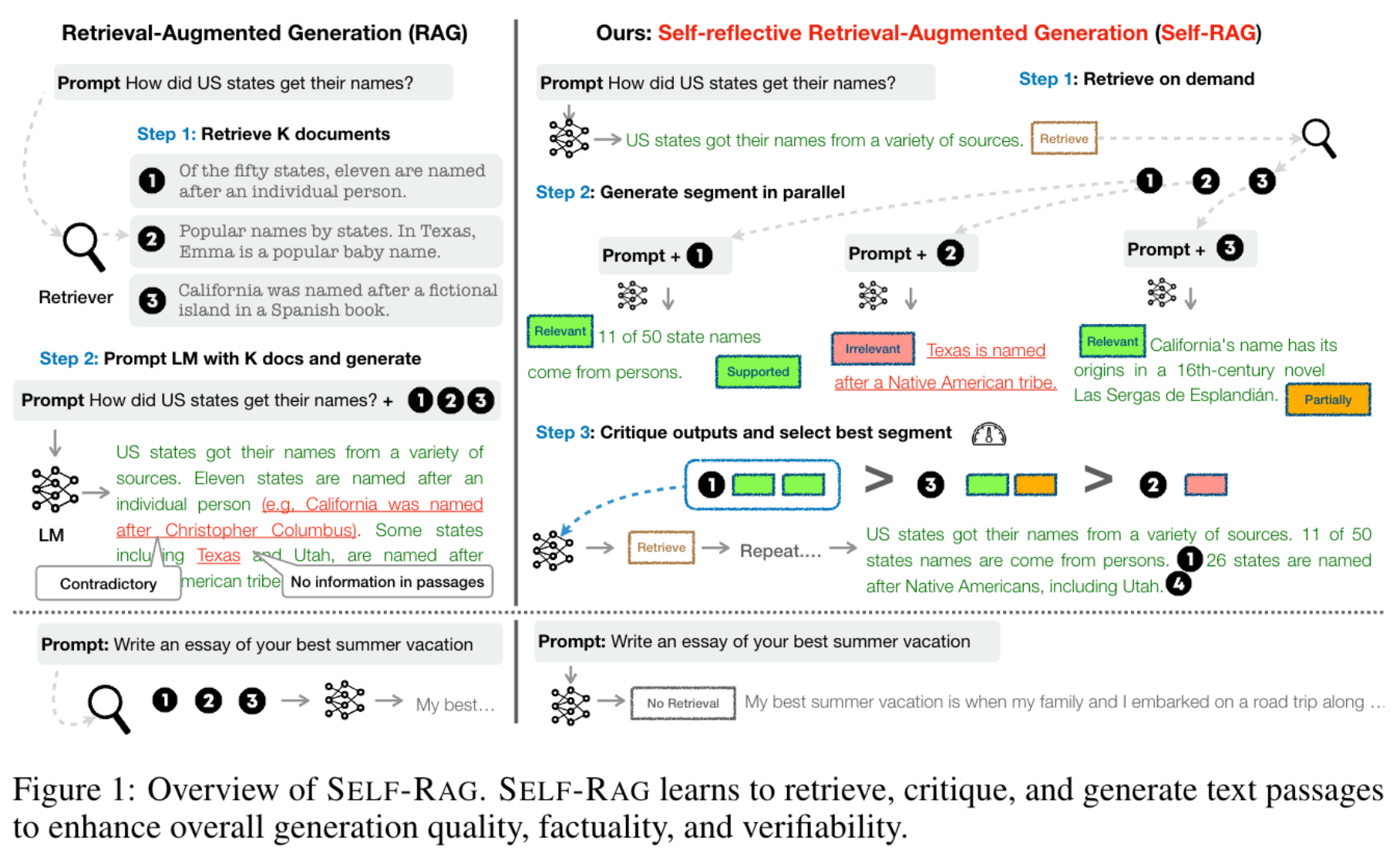
核心实现方法是在 Rag 流程中 (模型训练和推理) 引入 4 类特殊的 token

intuitively,
1.Retrieve token 是标记是否要触发检索
2.IsRel 标记是否是相关的: 不相关/相关,相当于一个粗筛
3.IsSupport 标记有帮助的程度 没帮助/部分有帮助/没帮助
4.IsUse 标记答案是对原始的 query 是有帮助的, 分 5 级打分
Self-Rag Inference
我们从 Self-Rag 推理流程中感受下 Self-Rag 工作流

intuitively,
1.对应 “Retrieve=No” 的推理, 直接输出无需检索 + 最终答案
2.对应到 “Retrieve=Yes” 的推理,思想是顺序执行 3 个步骤:
(i). 判断 “这问题我需要查资料吗?” (对应第一次推理:生成 Retrieve=Yes)
比如你被问 “2024 巴黎奥运会开幕时间”—— 你知道这是 “时效性事实”,自己记不准,所以决定 “要查资料”(对应模型输出 Retrieve=Yes)
这一步模型只做 “二选一”(要查/不要查) ,像人快速判断 “自己会不会” 一样,1 秒出结果
(ii). 查完资料,先挑 “有用的留下” (对应第二次推理:生成 ISREL 标记)
你查资料时,可能搜出 3 篇:A 篇讲 “开幕时间 7 月 26 日”,B 篇讲 “门票价格”,C 篇讲 “东京奥运会回顾”—— 你会自动留下 A 篇,扔掉 B、C(对应模型给 A 标ISREL=Relevant,B、C 标 Irrelevant)
这一步也很自然:模型只做 “有用/没用” 的筛选,像人翻书时跳过无关章节,不用动复杂脑筋
(iii). 用有用的资料回答,再确认 “没说错”(对应第三次推理:生成响应 +ISSUP标记)
你根据 A 篇 “7 月 26 日开幕”,组织语言回答 “巴黎奥运会 7 月 26 日开幕”—— 同时心里确认 “这话是从 A 篇来的,没瞎编”(对应模型生成响应,标 ISSUP=Fully Supported)
这一步更简单:模型先 “抄重点”(从资料里提关键信息) ,再 “打勾确认”(验证没编内容) ,和人 “先摘抄再核对” 完全一样
Self-Rag 训练样本构造
构造样本将整个 self-rag 的流程全部写入到 response 里面, 相当于模拟一个顺序执行的过程, 顺序执行过程中根据检索-评判-最终回复的逻辑进行构造
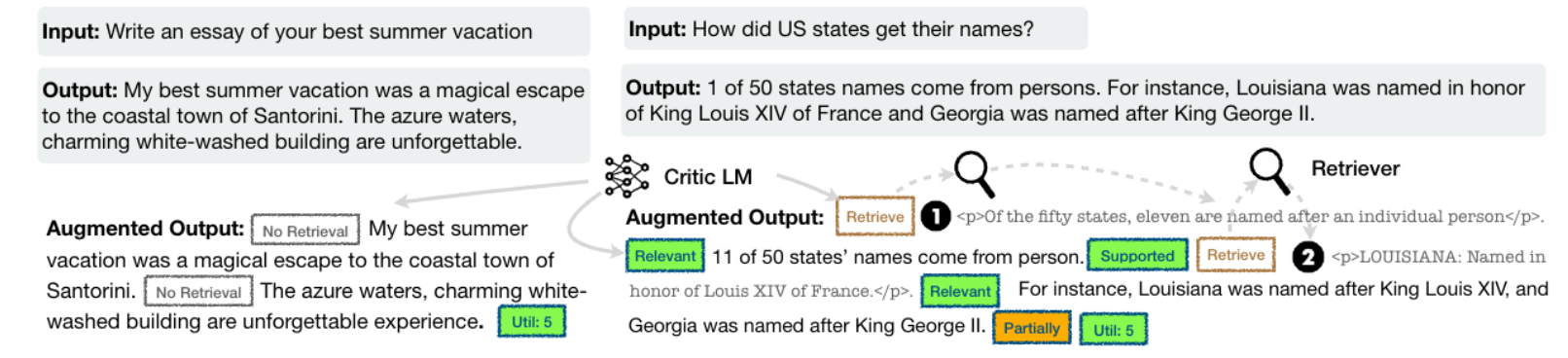
给出一些构造样本示例

self-rag 训练样本构造第一眼看十分复杂且反直觉, 复杂性疑惑是为什么不划分多个阶段设计样本而是要构造一个如此复杂的决策样本, 反直觉疑惑是用
<p>content</p>
包裹的检索段落为什么可以直接加入到 response, 以下是 doubao 给出的一些解释:
样本构造复杂性的解释
1.样本设计的 “序列化编码”:把多步骤流程变成 “一句话”
SELF-RAG 的训练样本本质是将 “检索决策=>文档筛选=>生成=>验证” 的多步骤流程,编码成连续的文本序列 (类似一句话包含完整逻辑)
例如:用户查询:"巴黎奥运会开幕时间?"=>
[Retrieve=Yes]=><p>文档:7月26日开幕...</p>=>[ISREL=Relevant]=>响应:7月26日开幕=>[ISSUP=Fully Supported]=>[ISUSE=5]
对自回归语言模型(如 GPT 类模型) 而言,这种序列与普通文本(如一篇文章) 没有本质区别——模型的目标始终是 "根据前文预测下一个 token". 在训练中,模型会学到:
看到 "事实性查询",下一个 token 应该是[Retrieve=Yes]
看到[Retrieve=Yes]和<p>文档内容</p>,下一个 token 应该是[ISREL=Relevant](如果文档相关)
看到[ISREL=Relevant]和文档,下一个 token 应该是 "基于文档的响应",再之后是[ISSUP=Fully Supported]...
就像人学说话时,会自然掌握 “先问候=>再提问=>再回答” 的序列逻辑,模型通过大量类似样本的训练,也能掌握这些标记的 “出现顺序” 和 “触发条件”
2.标记的 “强关联性约束”:避免不同标记的逻辑冲突
样本中不同标记的出现并非随机,而是存在严格的前后依赖关系,这种约束让模型能清晰区分不同标记的功能:
Retrieve必须是序列的第一个标记 (先决策是否检索,再做后续操作)
ISREL必须紧跟在<p>文档</p>之后 (先有文档,再评估相关性)
ISSUP必须紧跟在 "响应内容" 之后 (先有回答,再验证支持度)
所有标记的语义必须自洽(如ISREL=Irrelevant的文档,不能支撑ISSUP=Fully Supported的响应)
这种 "顺序约束 + 语义自洽",就像给模型画了一张 "流程图"—— 例如,模型绝不会在 Retrieve=No后 生成<p>文档</p>(因为无需检索就不会有文档) ,也不会在无文档的情况下生成ISREL标记. 通过大量样本的重复强化,模型会逐渐形成 "标记使用的条件反射"
举个通俗例子:像学写 "实验报告" 一样自然
可以把这种训练类比成 "教学生写实验报告"
实验报告的固定结构是 "实验目的=>是否需要器材(Retrieve) =>记录器材参数(文档) =>判断器材是否适用(ISREL) =>实验步骤与结果(响应) =>结果是否符合器材特性(ISSUP) =>实验是否成功(ISUSE) "
学生一开始可能不懂,但通过反复仿写完整报告,会自然掌握 "每个部分的位置和作用"—— 比如 "判断器材是否适用" 必须在 "记录器材参数" 之后,"结果是否合理" 必须基于 "实验结果" 和 "器材特性".
SELF-RAG 的模型也是如此:通过大量包含完整标记序列的样本训练,会逐渐掌握 "何时输出何种标记",尽管流程看起来复杂,但对模型而言只是 "学习一个更长的句子结构" 而已
3.总结:复杂流程的本质是 “逻辑的显式化”,而非 “实现的复杂化”, SELF-RAG 的 “复杂” 体现在 “把隐性逻辑显式化” (用标记写出所有步骤) ,但对模型的训练方式并未改变 —— 仍是标准的 “预测下一个 token” 的自回归学习. 样本中所有标记的共存,恰恰是为了让模型清晰学到 “每一步该做什么”,最终实现 “检索 - 生成 - 验证” 的无缝衔接,反而比 “隐式逻辑” 更易训练出可靠的模型
检索样本加入训练 response 的解释
我的问题: 始终感觉这个样本设计非常奇怪,训练应该是 sft 训练,sft 训练的 response 里面居然有很多 \
\
包裹的检索段落,这我感觉让模型产出幻觉的可能性超高
如下是豆包的一个原始回答, 强调了\
这种标记的出现其实是一种特殊识别标记且在推理过程中只要过滤掉就行, 但是感觉很难完全说服我:
你的顾虑非常合理, 从传统 SFT(监督微调) 的认知来看,"将检索段落嵌入模型输出(response) " 确实违背了 "输出仅为任务响应" 的常规设计,很容易让人担心模型会误学 "生成冗余文档片段" 甚至产生幻觉. 但结合 SELF-RAG 的核心目标(让模型学会 "利用检索文档" 而非 "生成文档") 和训练机制(标记与内容的强绑定约束) ,这种设计反而能抑制幻觉,而非促进幻觉,具体可从以下 3 个关键角度拆解:
一、先明确:SELF-RAG 的 SFT 训练目标与传统 SFT 完全不同
传统 SFT 的目标是 "让模型根据输入生成符合人类偏好的任务响应"(如直接回答 "内存类型""播出时间") ;而 SELF-RAG 的 SFT 目标是 "让模型学会 **‘检索决策 - 文档评估 - 基于文档生成’的全流程逻辑 **"—— 模型需要学习的不是 "如何生成检索文档",而是 "如何识别‘何时需要调用检索文档’‘如何基于检索文档生成可靠响应’".
因此,训练样本中<p></p>包裹的检索段落,本质是 **"给模型的‘参考素材’标注"**,而非 "让模型生成的目标内容". 就像教学生写作文时,会给一段参考资料并标注 "这段资料用于论证 XX 观点",学生需要学的是 "如何用资料",而非 "复制资料"——SELF-RAG 的<p>标签就是 "参考素材的明确标识",帮助模型区分 "哪些是外部素材,哪些是需要生成的响应".
二、<p></p>标签 + 反思标记的强约束:从训练机制上避免模型 "误生成文档片段"
SELF-RAG 的样本设计中,<p>标签并非孤立存在,而是与Retrieve/ISREL/ISSUP等反思标记强绑定,形成 "素材 - 决策 - 验证" 的闭环约束,从根源上防止模型将文档片段当作 "响应内容" 生成:
1. <p>标签的 "身份标识" 作用:明确区分 "检索素材" 与 "任务响应"
样本中<p>片段的出现有严格规律:仅在Retrieve=Yes之后、ISREL标记之前出现,且格式固定(<p>文档...</p>) . 这种固定位置 + 固定格式,相当于给模型传递一个明确信号:"<p>里面的是外部检索来的参考素材,不是你需要生成的最终回答;你需要生成的是ISREL标记之后、ISSUP标记之前的文本(任务响应) ".
例如 Table 4 中 "查询《行尸走肉》第七季时间" 的样本:[Retrieve=Yes]<p>...premiered on October 23, 2016...</p>[ISREL=Relevant]October 23, 2016[ISSUP=Fully Supported]模型能清晰学到:<p>里的长文本是 "素材",而[ISREL]之后的 "October 23, 2016" 才是 "需要生成的响应"——<p>标签反而成了 "素材边界" 的清晰标识,避免模型混淆 "素材" 和 "响应".
2. 反思标记的 "验证约束":强制模型生成 "有素材支撑的响应"
样本中的ISREL(文档相关性) 和ISSUP(响应支持性) 标记,进一步给模型施加 "必须基于<p>素材生成响应" 的约束:
若模型生成的响应与<p>素材无关(如<p>说 "2016 年开播",模型却生成 "2018 年") ,则ISSUP标记会标注为None,这种 "响应 - 标记不匹配" 的样本会让模型在训练中调整参数,避免无依据生成;
若模型误将<p>素材直接复制为响应(如把<p>里的整段文本当作回答) ,则ISSUP虽可能为Fully Supported,但ISUSE(效用) 标记会标注低分(因响应冗余、未提炼核心信息) ,同样会让模型学习 "需提炼素材而非复制素材".
这种 "标记约束" 本质是让模型在训练中形成条件反射:"生成响应前必须先看<p>素材,响应必须能被素材支撑,否则会被‘惩罚’(低效用评分) "—— 这反而比传统 SFT(无素材参考,全靠模型记忆) 更能抑制幻觉.
三、推理阶段的 "流程隔离":训练时的<p>素材不会出现在最终用户输出中
最关键的一点是:训练样本中<p>包裹的检索素材,仅用于训练阶段 "教模型如何用素材",在推理阶段不会出现在给用户的最终输出中.
推理时的实际流程是:
模型判断 Retrieve=Yes,触发检索器获取新的文档(非训练样本中的<p>素材)
模型 "默读" 检索到的新文档(不展示给用户) ,基于文档生成响应
给用户的输出仅包含 "任务响应"(如 "《行尸走肉》第七季于 2016 年 10 月 23 日开播") ,可选展示ISREL/ISSUP标记(增强可解释性) ,但绝不会展示<p>包裹的原始检索文档.
训练时让模型 "看到<p>素材",是为了让它学会 "如何处理推理时遇到的新素材";而推理时模型不会 "生成<p>素材",只会 "利用新素材生成响应"—— 这就像学生训练时看参考资料做题,考试时不会把参考资料写进答卷里一样,不存在 "生成冗余文档片段" 的问题.
总结:看似 "奇怪" 的设计,实则是为了更精准地抑制幻觉
你觉得样本设计 "奇怪",本质是因为它打破了传统 SFT "输入 - 纯响应" 的简单范式;但从 SELF-RAG 的核心目标(让模型学会 "可控利用外部知识") 来看,这种 "<p>素材 + 标记约束" 的设计恰恰是 "反幻觉" 的关键:
传统 SFT 的幻觉源于 "模型靠记忆生成,无外部素材验证";
SELF-RAG 的训练样本通过<p>素材提供 "外部验证依据",再通过标记强制模型 "基于依据生成",本质是给模型装上 "知识锚点",让它无法凭空生成无依据内容 —— 这也是为什么 SELF-RAG 在事实性任务上的幻觉率远低于传统 LM 的核心原因.
Self-Rag: 应用思考
1.整体方案复杂度还是比较高的,如果实际应用的话有个关键区别是用户不看到结合资料的合理性评估结果, 一方面可以借鉴是否触发检索决策思想: 通过引入 token 去标记去标记是否需要触发检索的状态
2.个人感觉结合资料合理性评估 + 触发时机还是解耦开训练比较容易锁定问题, 而不是混合在一起
Reference
[1]. Self-Rag: Learning To Retrieve, Generate, And Critique Through Self-Reflection.
转载请注明来源 goldandrabbit.github.io