Key Insights On SwallowCode/SwallowMath
1.对 Code 预训练数据进行改写,得到 SwallowCode 实现风格一致且代码语义重写的高质量预训练数据
2.对 Math 预训练数据进行数据清洗,得到 SwallowMath 实现更好的格式遵循
SwallowCode 重写流程

Code 数据集采用 he-stack-v2-train-smol-ids,在此基础上进行改写,总共分为过滤和改写 2 个核心步骤: 过滤和改写
Filter 过滤
1.Syntax error filter 语法错误过滤
利用 Python 语言内置的 compile() 对样本过滤掉无法通过的编译的代码
code = """
for i in range(3):
print("Hello", i)
"""
compiled = compile(code, "<string>", "exec")
exec(compiled)
2.Linter filter 基于 pylint 的过滤
pylint 是 Python 生态中最经典、功能最强的 代码静态分析工具 (linter): 利用 pylint 代码检查工具进行 0-10 分的打分,如果高于如果分数低于 7.0 分就过滤掉; 分数在计算的时候同步融合了一个注释长度惩罚,这里认为代码注释长度越多,那么分数就更低, 目标是惩罚过度依赖注释来掩盖逻辑, 鼓励简洁、可读、语义清晰的代码
pylint 的使用
pylint --disable my_script.py
输出类似
************* Module my_script
my_script.py:3:0: C0114: Missing module docstring (missing-module-docstring)
my_script.py:5:4: C0103: Variable name "x" doesn't conform to snake_case naming style (invalid-name)
------------------------------------------------------------------
Your code has been rated at 7.50/10
然后对过长的代码注释进行惩罚
import tokenize
from io import StringIO
def check_comment_ratio(code: str):
"""
计算代码中注释行所占的比例(comment ratio)。
参数: code (str): 输入的 Python 源代码字符串。
返回: float: 注释行占总代码行数的比例,范围 [0, 1]。如果解析出错,返回 0。
"""
total_lines = 0 # 统计所有 token 的数量
comment_lines = 0 # 统计注释 token 的数量
try:
# 使用 Python 内置的 tokenize 模块对代码进行词法分析
tokens = tokenize.generate_tokens(StringIO(code).readline)
# 遍历所有 token
for token_type, _, _, _, _ in tokens:
total_lines += 1 # 每个 token 算作一行(粗略近似)
# 判断是否为注释 token
if token_type == tokenize.COMMENT:
comment_lines += 1
except tokenize.TokenError as e:
# 捕获无法正确解析 token 的情况
print(f"Token error encountered: {str(e)}")
return 0
except IndentationError as e:
# 捕获缩进错误
print(f"Indentation error encountered: {str(e)}")
return 0
# 如果没有有效 token,返回 0
if total_lines == 0:
return 0
# 计算注释比例
return comment_lines / total_lines
def apply_comment_penalty(score: float, comment_ratio: float) -> float:
"""
根据注释比例对得分进行惩罚(penalty)。
参数: score (float): 原始分数。comment_ratio (float): 注释比例。
返回: float: 惩罚后的新分数。
"""
# 如果全是注释(即代码没有实际内容),分数为 0
if comment_ratio == 1.0:
return 0.0
# 如果有部分注释,则按比例衰减
elif comment_ratio > 0:
penalty_factor = 1 - comment_ratio
score *= penalty_factor
# 返回最终分数
return score
3.LLM-based 过滤
除了语法和静态分析工具,同步利用代码评估质量的标准 Google Python Style Guide 来打分, 只保留 6 分以上的数据; 但发现这种方法成本比较高,标准流程中没有采用这种方法
You are a smart software engineer. Please evaluate the following code on a
scale of 1 to 10 based on the following criteria:
1. Are variable names descriptive and consistent with naming conventions?
2. Are comments and docstrings appropriately written to explain the purpose
and functionality of the code?
3. Are type annotations used effectively where applicable?
4. Are functions appropriately modularized, with well-defined
responsibilities and clear separation of concerns?
5. Are variables’ lifetimes intentionally managed, avoiding frequent
reassignment or overly long scopes?
6. Is error handling implemented appropriately where necessary?
7. Is the code properly indented and follows standard formatting guidelines?
8. Do comments provide context and rationale, rather than merely describing
what the code does?
9. Are functions and classes designed with clear, single responsibilities?
10. Is the code formatted in a way that enhances readability?
你是一名聪明的软件工程师。请根据以下标准,对下面的代码进行1到10分的评分:
1. 变量名是否具有描述性,且符合命名规范?
2. 注释和文档字符串是否恰当,能够解释代码的用途和功能?
3. 类型注解是否在适用处得到有效使用?
4. 函数是否进行了适当的模块化,具有明确的职责和清晰的关注点分离?
5. 变量的生命周期是否经过有意管理,避免频繁重赋值或过长的作用域?
6. 是否在必要处适当实现了错误处理?
7. 代码缩进是否正确,是否遵循标准格式指南?
8. 注释是否提供了背景信息和理由,而非仅仅描述代码的作用?
9. 函数和类的设计是否具有明确的单一职责?
10. 代码的格式是否有助于提高可读性?
Rewriting 改写
1.Style-Guided Code Rewriting 代码风格改写
这一步只改风格,不改内容,内容放在下一步再改, 这里基于 Google Python Style Guide 进行风格改写
You are a smart software engineer. Please evaluate the following code on a
scale of 1 to 10 based on the following criteria:
1. Are variable names descriptive and consistent with naming conventions?
2. Are comments and docstrings appropriately written to explain the purpose
and functionality of the code?
3. Are type annotations used effectively where applicable?
4. Are functions appropriately modularized, with well-defined
responsibilities and clear separation of concerns?
5. Are variables’ lifetimes intentionally managed, avoiding frequent
reassignment or overly long scopes?
6. Is error handling implemented appropriately where necessary?
7. Is the code properly indented and follows standard formatting guidelines?
8. Do comments provide context and rationale, rather than merely describing
what the code does?
9. Are functions and classes designed with clear, single responsibilities?
10. Is the code formatted in a way that enhances readability?
And provide suggestions for improvement based on the evaluation criteria.
You can also provide an improved version of the code in the following style:
21
### Evaluation: 7
### Suggestions: Provide specific, actionable suggestions to improve the
code based on the evaluation criteria.
### Improved Code: Provide a revised version of the code incorporating the
suggested improvements.
‘‘‘python
def improved function(arg1: int, arg2: str) -> str:
# Your improved code here
pass
‘‘‘
2.Self-Contained Optimiztion Rewrtiting 自包含优化重写
这一步直接用如下 prompt 生成新的重写代码
You are a smart software engineer. Please change a given code into
self-contained and well-structured code following the below best practices
and pythonic way.
1. Use meaningful variable and function names.
2. Write a clear and concise docstring for the function.
3. Use type hints for the function signature.
4. Write a clear and concise comment for the code block.
5. Ensure the code is self-contained and does not depend on external
variables.
6. Ensure the code is well-structured and easy to read.
7. Ensure the code is free of errors and runs correctly.
8. Ensure the code is optimized and does not have redundant operations.
9. Ensure the algorithm and data structures are efficient and concise.
If given code is not self-contained or too simple, please change it to a
more educational and useful code.
你是一名聪明的软件工程师。请按照以下最佳实践和 Python 风格,将给定代码修改为自包含且结构良好的代码:
1. 使用有意义的变量名和函数名。
2. 为函数编写清晰简洁的文档字符串。
3. 在函数签名中使用类型提示。
4. 为代码块编写清晰简洁的注释。
5. 确保代码是自包含的,不依赖外部变量。
6. 确保代码结构良好且易于阅读。
7. 确保代码没有错误且能正确运行。
8. 确保代码经过优化,没有冗余操作。
9. 确保算法和数据结构高效简洁。
SwallowMath 重写流程
SwallowMath 相对比较简单, 采用 finemath-4+ 的数据进行清洗, 属于比较常规操作, 评估数据换成了数学相关数据集, 改写提示词包含五个部分:
(1) remove residual web headers, footers, and privacy notices;
(2) delete extraneous metadata such as question and answer timestamps;
(3) fill in missing context when either the question or answer is incomplete;
(4) rewrite explanations to be concise yet information-dense;
(5) present a clear step-by-step solution
翻译如下:
1. 删除残留的网页页眉、页脚和隐私声明;
2. 删除多余的元数据,例如问题和回答的时间戳;
3. 当问题或答案不完整时,补充缺失的上下文;
4. 重写解释,使其既简洁又信息量丰富;
5. 提供清晰的逐步解题方案。
给出一个 prompt template
You are an intelligent math tutor. You are given the following math problem
and answer with some unnecessary parts. Please remove the unneeded parts of
the questions. For example, the date of the question submitted, the answer
date, the privacy policy, the footer, the header, etc., should be removed.
However, please keep the main question and answer.
If questions or answers lack some information or are not elaborate, please
make them more informative and easy to understand. If needed, please add
more detail about the step-by-step calculation process.
你是一名智能数学辅导老师。现有一道数学题及答案,其中包含部分无关内容,请删除题目中的冗余信息。例如,题目提交日期、答案日期、隐私政策、页脚、页眉等均需删除,但需保留核心题目与答案部分。
若题目或答案存在信息缺失、表述不够详尽的情况,请补充信息使其更易懂;必要时,需增加详细的分步计算过程说明。
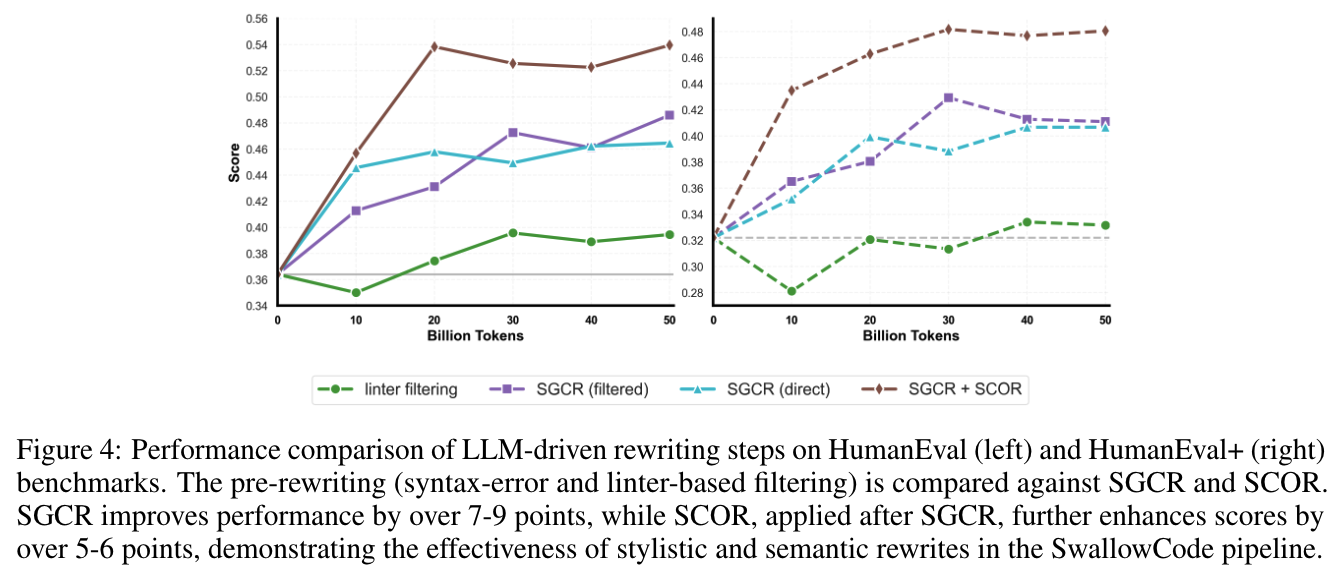
对比了在 HumanEval 和 HumanEval+ 上的效果对比,发现风格改写 SGCR 提升 7-9 个百分点,自包含优化重写提升 5-6 个百分点
Reference
[1]. Rewriting Pre-Training Data Boosts LLM Performance in Math and Code.
转载请注明来源 goldandrabbit.github.io