Key Insights On Reflective Memory Management
1.提出 Reflective Memory Management (RMM) 反思式记忆管理框架, 包括 Prospective Reflection 和 Retrospective Reflection 两个阶段,Prospective Reflection 解决固定的记忆抽取粒度下的提取记忆表征过于碎片化或者过于不完整的问题, Retrospective Reflection 通过训练 reranker 模块提升结合记忆使用最优性问题
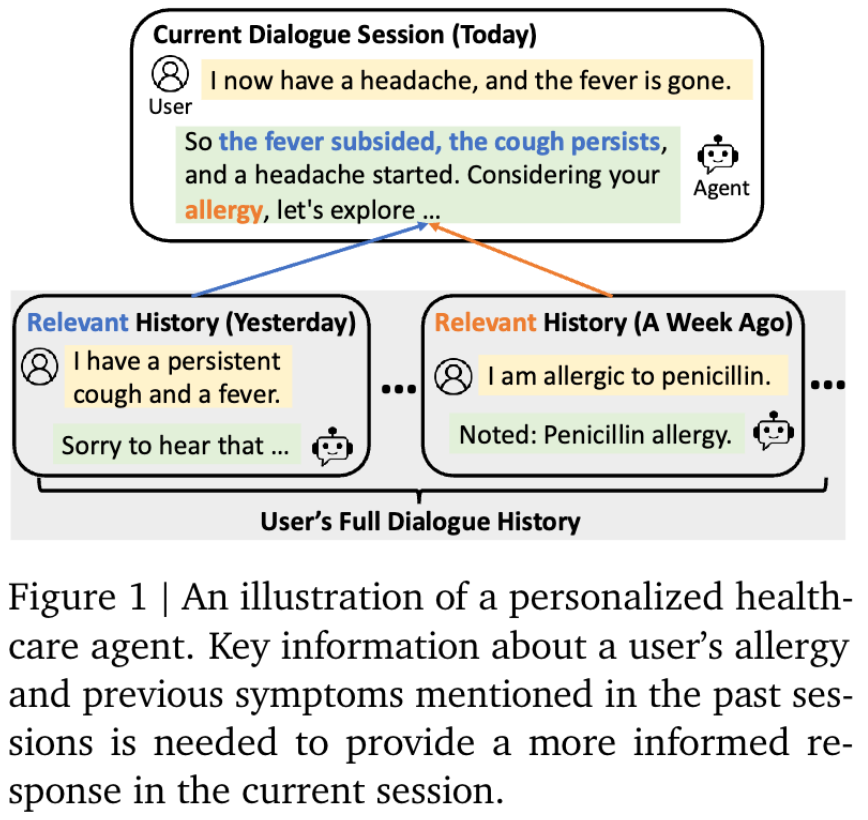
Reflective Memory Management 反思式记忆管理
Reflective Memory Management 反思式记忆管理框架分为四个部分
1.memory bank: 按照
2.retriever (检索器): 给定当前的 query, 检索相关的记忆, 输出相关记忆的集合
3.reranker (重排器): 基于 retriever 的输出结果,找到最相关的 TopK 记忆
4.LLM (语言模型): 合并记忆和当前 context 产出个性化的回复
Reflective Memory Management 反思式记忆管理核心分为2个关键流程
1.Prospective Reflection: Topic-Based Memory Organization 前瞻性反思: 基于话题的记忆组织
2.Retrospective Reflection: Retrieval Refinement via LLM Attribution 回顾性反思: 让语言模型回顾并归因过去的对话决策进而改善记忆检索过程
Prospective Reflection 前瞻性反思
Prospective Reflection 前瞻性反思实现了基于话题的记忆组织结构,主要分为两个关键流程 memory extraction (记忆抽取) 和 memory update (记忆总结)
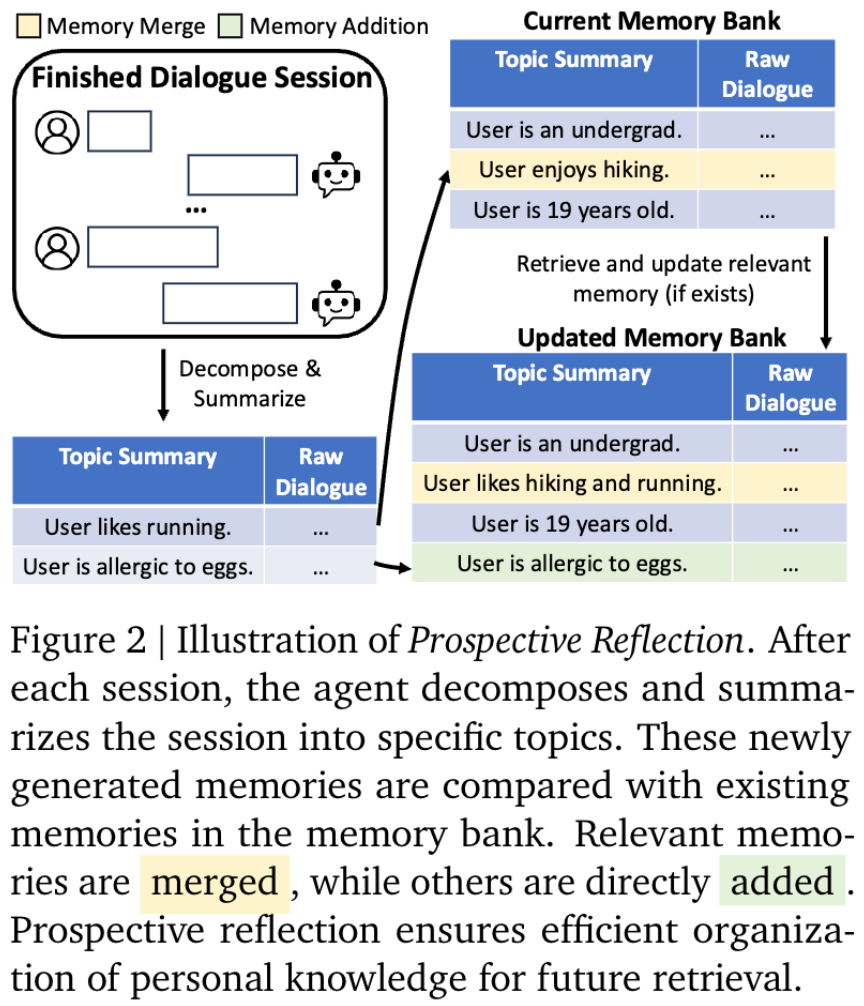
Memory Extraction 记忆抽取
1.记忆抽取的结构按照
2.双重抽取: 对话双方 speaker1 和 speaker2 分别抽取一次, 抽取的格式采用 “主语+谓语格式”, 例如 “讲话者A住在英格兰,经历较多大雾或者下雨天气,但是喜欢秋天”, 如下给出了 speaker1 的记忆抽取 prompt:
**Task Description**: Given a session of dialogue between SPEAKER_1 and SPEAKER_2, extract the
personal summaries of SPEAKER_1, with references to the corresponding turn IDs. Ensure
the output adheres to the following rules:
* Output results in JSON format. The top-level key is "extracted_memories". The value
should be a list of dictionaries, where each dictionary has the keys "summary" and
"reference":
– summary: A concise personal summary, which captures relevant information about
SPEAKER_1's experiences, preferences, and background, across multiple turns.
– reference: A list of references, each in the format of [turn_id] indicating
where the information appears.
* If no personalsummarycan be extracted, return NO_TRAIT.
Example:
INPUT:
* Turn 0:
– SPEAKER_1: Did you check out that new gym in town?
– SPEAKER_2: Yeah, I did. I'm not sure I like the vibe there, though.
* Turn 1:
– SPEAKER_1: What was wrong with it?
– SPEAKER_2: The folks there seemed to care more about how they looked than working
out. It was a little too trendy for me. I'm pretty plain.
* Turn 2:
– SPEAKER_1: Ah, got it. Well, maybe one of the older gyms will work out better
for you—or I guess you could get that treadmill you were talking about before.
Are you leaning one way or the other yet?
– SPEAKER_2: I'm leaning towards the treadmill. I think it will work better for
my lifestyle. I just don't know which type to get. There are so many choices
out there. Do you use a treadmill at your gym? Do you have a suggestion for a
home one?
* Turn 3:
– SPEAKER_1: I usually just lift weights there, to be honest. But I think I've
heard good things about the NordicTrack?
– SPEAKER_2: Yeah, I've heard good things about that, too. I like the idea of a
multi-exercise piece of equipment. As long as the weather isn't too bad, then
I prefer to go for a run. But since it rains quite a bit here, I like the idea
of an inside option. How is the weather in New England?
* Turn 4:
– SPEAKER_1: Oh, it can get pretty foggy and rainy here too, I'm afraid. But
as I'm sure you've heard, it's really beautiful in the fall! Are there four
distinct seasons where you are, too?
– SPEAKER_2: Yes, I've heard about the fall colors. I may get there one day. Yes,
we have seasons—rain, lighter rain, summer, and more rain! Ha!
* Turn 5:
– SPEAKER_1: Haha! I lived overseas in the tropics once. Sounds just like it!
– SPEAKER_2: The tropics sound great. It's not as warm as the tropics, but I like
it. I'm from Alaska, so I'm pretty weather-tough.
OUTPUT:
{
"extracted_memories":
[
{
"summary": " SPEAKER_1 asked about a new gym in town and suggested older gyms or
a treadmill as alternatives.",
"reference": [0,2]
},
{
"summary": " SPEAKER_1 usually lifts weights at the gym rather than using a
treadmill.",
"reference": [3]
},
{
"summary": " SPEAKER_1 has heard good things about the NordicTrack treadmill.",
"reference": [3]
},
{
"summary": " SPEAKER_1 lives in New England and experiences foggy and rainy
weather but enjoys the fall season.",
"reference": [4]
},
{
"summary": " SPEAKER_1 has lived overseas in the tropics before.",
"reference": [5]
}
]
}
Task: Follow the JSON format demonstrated in the example above and extract the personal
summaries for SPEAKER_1 from the following dialogue session.
Input: {}
Output:
Memory Update 记忆更新
memory update 模块实现了将最新抽取的记忆如何合并到 memory bank 的流程: 对于每一条新抽取的 memory,从 memory bank 中检索 TopK 条语义最相关的记忆, 然后通过一个 LLM 判定应该是 add 新增到 memory bank 中, 还是 merge 融合到已有的记忆中, 使用的 prompt 如下:
**Task Description**: Given a list of history personal summaries for a specific user and a new and similar personal summary from the same user, update the personal history summaries
following the instructions below:
* Input format: Both the history personal summaries and the new personal summary are provided in JSON format, with the top-level keys of "history_summaries" and "new_summary".
* Possible update actions:
– Add: If the new personal summary is not relevant to any history personal summary, add it.
Format: Add()
– Merge: If the new personal summary is relevant to a history personal summary, merge them as an updated summary.
Format: Merge(index, merged_summary)
Note: index is the position of the relevant history summary in the list.
merged_summary is the merged summary of the new summary and the relevant history
summary. Two summaries are considered relevant if they discuss the same aspect
of the user's personal information or experiences.
* If multiple actions need to be executed, output each action in a single line, and
separate them with a newline character ("\n").
* Do not include additional explanations or examples in the output—only return the
required action functions.
Example:
INPUT:
* History Personal Summaries:
– {"history_summaries": ["SPEAKER_1 works out although he doesn't particularly enjoy it."]}
* New Personal Summary:
– {"new_summary": "SPEAKER_1 exercises every Monday and Thursday."}
OUTPUT ACTION:
Merge(0, SPEAKER_1 exercises every Monday and Thursday, although he doesn't particularlyenjoy it.)
Task: Follow the example format above to update the personal history for the given case.
INPUT:
* History Personal Summaries: {}
* New Personal Summary: {}
OUTPUT ACTION:
intuitively,
1.这个 prompt 是分割了多个动作执行,
(i). 对抽取的最新的记忆检索语义最相似的记忆
(ii). 用一个 Prompt 判断是应该做哪种操作是新增还是合并,如果是合并,那么需要将合并的源数据标记并输出合并结果
(iii). 基于上一步的合并任务,再用一个 Prompt 去进行真正的合并动作,得到新的结果输出
Retrospective Reflection: Retrieval Refinement via LLM Attribution
Retrospective Reflection 的核心思想就是要实现一个高效的 reranker, reranker 能对检索回来的多个记忆进行排序,找到那些能够最有效结合后能实现更高质量回复的记忆, 也就是 <更高的记忆排序分 == 结合记忆得到更优质回复>
这里的 reranker 是怎么实现的呢? 训练了一个 listwise ranking 小模型,如果 reranker 能够有效对检索回来的记忆进行有效的排序,那么 LLM 结合之后得到更好的回复的概率就更大: 因此需要一个结合记忆得到更优回复的归因关系, 给到 reranker 模型去进行训练, 如何做到呢?核心思想是用 LLM 单独评估借助了 LLM 是否能有效利用记忆得到回复去构造样本训练出来这个 reranker
Reranker 的优化目标和结构设计
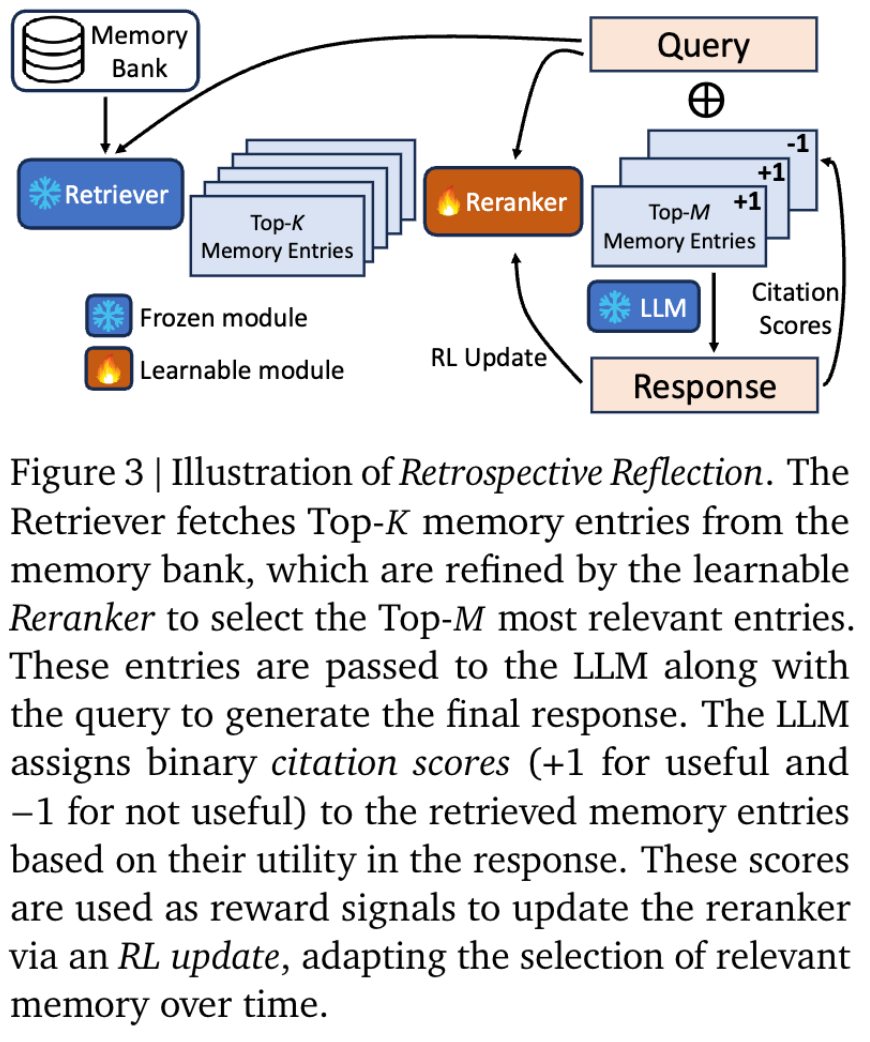
本质上是训练了一个单独的小网络实现 listwise ranking 排序的模型, 作用是对 topK 个样本排序:
reranker 输入: query $q$ 和 topK 条记忆 ${m_1,m_2,\ldots,m_k}$
reranker 输出: 一个相关性分数集合 $p={p_1,p_2,\cdots,p_k}$
reranker 的网络结构
(i). adaption 层
(ii). 计算条记忆打分
(iii). 分布层: 输出一个概率分布
Reranker 的样本生成与训练过程
先给定 query 和 retriever 召回回来的记忆,同时生成相应和每条记忆是否被使用的状态, 然后用如下 PE 生成
User Query: "What did I tell you about my vacation plans?"
Retrieved Memories:
[1] You mentioned going to Bali next week.
[2] You said you were tired of work.
[3] You talked about a new camera.
Generate a reply to the user.
Also indicate, for each memory, whether it was used (Yes/No) in your reasoning.
生成一个 LLM 自归因反馈 (LLM attribution)
Response:
"Yes, you said you were heading to Bali next week!"
Citations:
[1] Yes
[2] No
[3] No
然后基于这种方式: 如果是 citition score == Useful 就标注为 +1, 如果是 citition score == Not Userful 那么标注为 -1, 采用 reinforce algorithm 进行模型训练, 举个例子如下:
| Memory | 被引用? | Reward |
| :——- | :—- | :——- |
| m₁ | ✅ 是 | +1 |
| m₂ | ❌ 否 | -1 |
| m₃ | ❌ 否 | -1 |
然后我们如上防范构造样本进行 reinforce 训练, 目标是最大化记忆被引用的概率, 得到 reranker 模型
Reference
[1]. In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
转载请注明来源 goldandrabbit.github.io