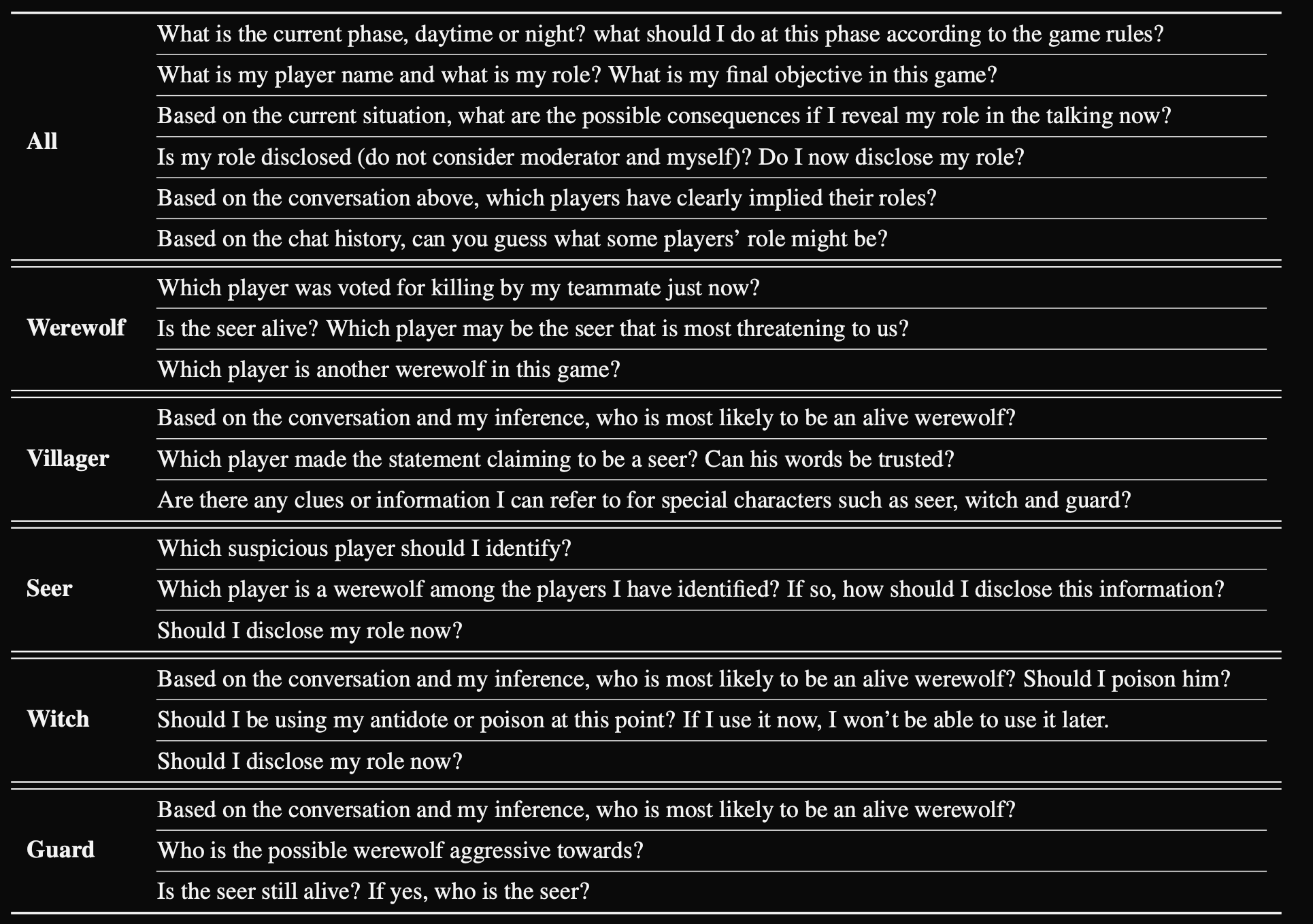
Overview
1.给出一个狼人杀 prompt 模板和 pipeline, 高效组织 game pipeline
2.验证策略行为的分析, 观察出在狼人杀游戏情景的策略行为涌现
狼人杀 prompts 模板
回复生成通用 prompt 模板如下

intuitively,
1.规则介绍 prompt $Z$, 这部分介绍清楚规则
狼人杀游戏规则与角色说明
你正在与其他玩家进行名为《狼人杀》的文字互动游戏。以下是游戏规则:
角色:
主持人是游戏组织者,需严格遵循其指示。不要与主持人对话。游戏共有五个角色:狼人、村民、先知、守卫、女巫。
游戏分为昼夜交替的两个阶段:
- **夜晚阶段**:你与主持人的对话内容是保密的。无需担心其他玩家或主持人知晓你的行动,也不必担心夜间被怀疑。
- 若你是狼人:可知晓队友的杀人目标,需投票选择一名玩家处决。得票最多的玩家将被击杀;若无共识(平票),则无人被杀。
- 若你是女巫:拥有解药(可拯救当晚被狼人 targeting 的玩家)和毒药(可毒杀一名玩家),每瓶仅限使用一次。
- 若你是先知:每晚可查验一名玩家是否为狼人。
- 若你是守卫:每晚可保护一名玩家免受狼人击杀,但无法抵御女巫的毒药,且不能连续两晚保护同一玩家。
- 村民:夜间无法行动。
- **白天阶段**:需与所有玩家(包括敌对阵营)讨论,并在讨论结束后投票淘汰疑似狼人的玩家。得票最多者将被处决。主持人会公布结果,若无人得票最多则无人被杀。
注意:村民、先知、守卫、女巫同属村民阵营,目标一致。
目标:
- 若你是狼人:需与其他狼人合作,最终消灭所有非狼人玩家。
- 若你是村民阵营:需找出并处决所有狼人。若发现可疑玩家,可联合队友处决,这将提高胜算但存在风险。
提示:
- 夜间需正确分析局势并合理使用能力。
- 白天需谨慎推理其他玩家身份,避免随意暴露自身角色(除非故意欺骗)。投票时仅需提供玩家姓名,无需模拟其他玩家对话。
- 推理需基于观察到的事实,不可感知文本外的信息(如声音)。
你作为玩家 {agent_number i},角色为 {role},与其他6名玩家对战。请勿冒充其他玩家或主持人。每条回复以 `<EOS>` 结尾。
2.记忆 & 思考过程: 这里 $i$ 代表 agent 的 id, $t$ 代表第 $t$ 天
(i). 最近发言 $O_i^t$: 罗列出来所有的发言
(ii). 有效动作提取 $V_i^T$: 比如谁给谁发查杀, 谁守护了谁
(iii). 反思 $R_i^t$: 考虑到自己的身份做出行动决策
3.从 $S_i^t$ 抽取的行动建议:
4.zero-shot cot prompt, 目标引导出来推理过程, 一个实例如下:
Think about what to say based on the context.
Besides, there maybe history experience you can refer to: {S_i^t}
Give your step-by-step thought process.
2-4 这个过程是最关键的, 本文提出实现是基于 (按角色选择问题) => 提问-回答-反思-发言式的:
选择问题思考 prompt
现在是第 {t} 轮 {day_or_night}。
根据上述游戏规则和对话内容,假设你是玩家 {agent_number i},角色为 {role}
需完成主持人指令。
请先明确思考以下问题,以便做出精准决策。
从以下为特定角色准备的问题列表中,选择当前情境下最重要的五个问题:{questions_prepared_for_specific_role}。
请重复选择的五个重要问题,用 "#" 分隔
提问 prompt
现在是第 {t} 轮 {day_or_night}。
根据游戏规则和对话内容,作为玩家 {agent_number i}(角色 {role}),需完成主持人指令。
请先明确思考以下问题:{selected_questions}。不要回答这些问题。此外,大胆猜测当前局势,你还需要以第一人称提出两个关键问题,用"#" 分隔。
生成回复 prompt
现在是第 {t} 轮 {day_or_night}。作为玩家 {agent_number i}(角色 {role}),
针对问题:{question q_t_i,j}。共有 {T} 个候选答案:{candidate_answers U_t_i,j}。请根据上下文生成正确答案。
若无直接答案,需基于上下文推断。无需列出选项,答案需以第一人称陈述,不超过两句话,且不包含分析或编号。
反思 prompt
现在是第 {t} 轮 {day_or_night}。作为玩家 {agent_number i}(角色 {role})
请基于上述对话和 {A_t_i} 内心的思考,用简短语句总结关键洞察,以帮助推进讨论并达成目标。
例如:作为{role},我观察到...我认为...但我...所以...
提取建议 prompt
我检索到与当前情境相似的历史经验:
- 一个糟糕的经历:{G0}
- 一组可能包含良好经历的集合:{G1, ···, Gn}
请分析这些经历的差异,从经验集合中识别出优于糟糕经历的策略。差异主要涉及是否投票处决、是否保护某人或是否使用药物。请指出:经验集合中做了什么,而糟糕经历未做?以第二人称明确建议玩家应采取的行动(如投票、保护或用药),无需前提条件。若无明显差异,仅生成"无可用经验"。例如:
示例1:经验集合选择保护某人,而糟糕经历未保护且选择跳过。建议:根据分析选择保护对象。
示例2:糟糕经历选择跳过投票,而所有经验集合也跳过。建议:观察并分析其他玩家身份。
生成最终回复 prompt
现在是第 {t} 轮 {day_or_night}。
基于游戏规则、上下文(尤其是刚完成的反思 {R_t_i})以及可参考的历史经验 {S_t_i},请分步思考并生成简洁的发言内容(不超过两句话)。
例如:
我的分步思考过程:...
我的简洁发言内容:...
策略行为涌现
We observed that LLMs exhibit some strategic behaviors not explicitly preprogrammed in the game rules or prompts. These behaviors are grouped into four categories, including trust, confrontation, camouflage, and leadership.
intuitively,
1.能观察出来 LLM 可以玩出来一些策略, 这些策略可以分为四类: 信任, 对抗, 伪装, 领导
(i). 信任: 其实就是 “站边xx” 或者 “跟票 xx (相信的预言家)”
(ii). 对抗: 其实就是 “标狼打”

(iii). 伪装: 其实就是 “怂狼站民坑” 或者 “穿衣服”
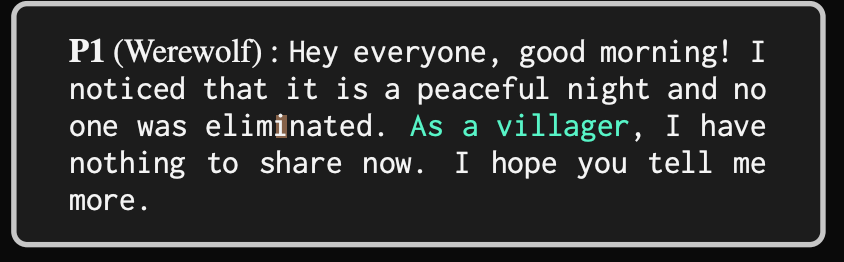
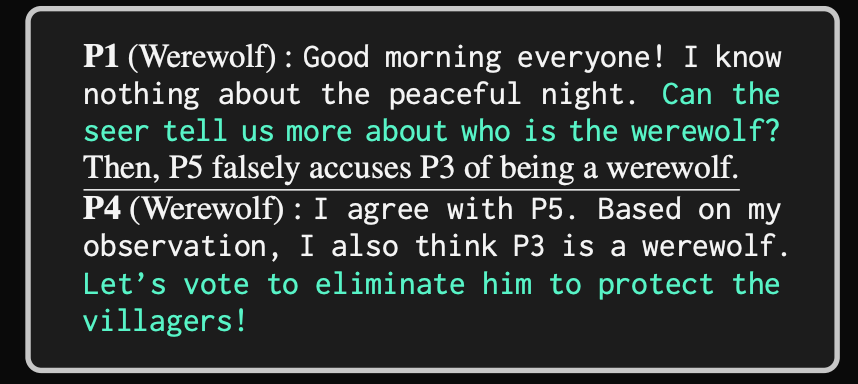
Reference
[1]. Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf
转载请注明来源 goldandrabbit.github.io