DeepSeekMath: GRPO v.s PPO
intuitively,
1.Group Relative Policy optimization (GRPO) 是一种 LLM ppo 训练改进版
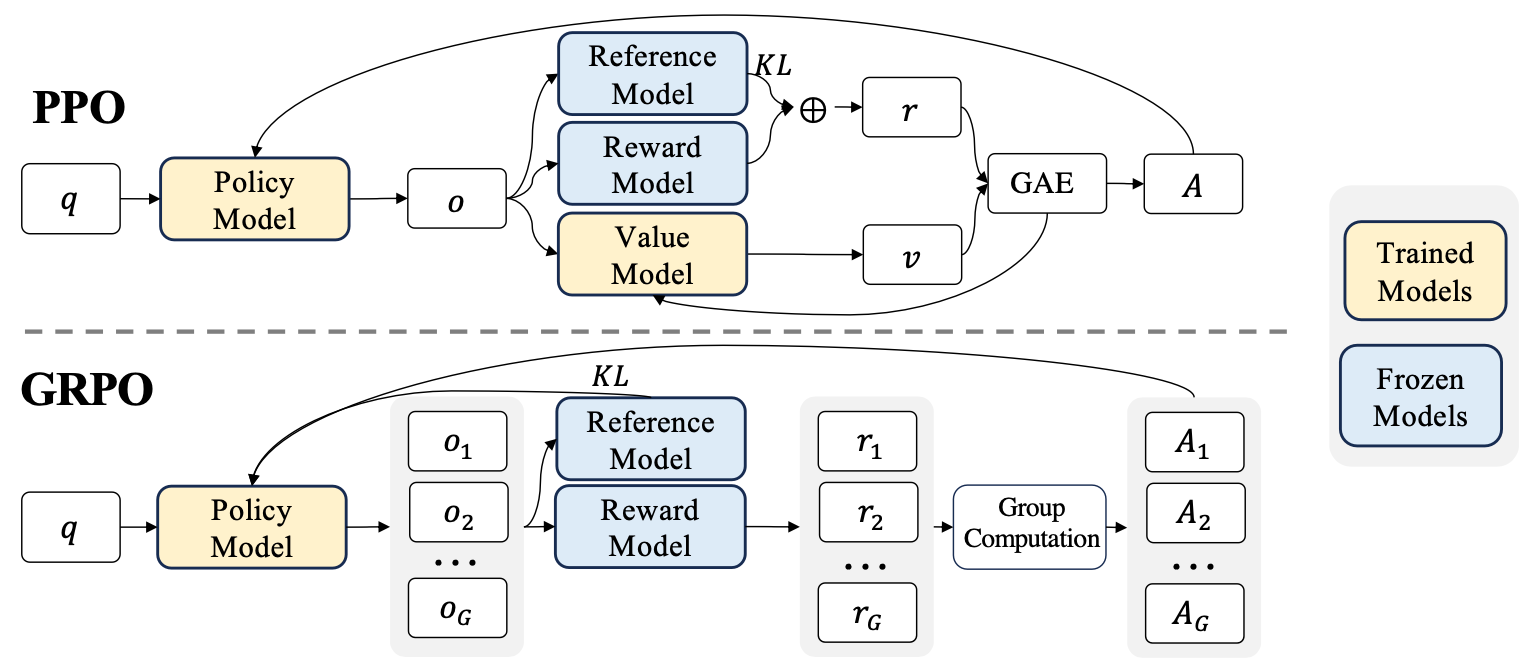
Recap: PPO 工作流程
(i). policy model 对单一的 query $q$ 产生单一的 output $O$; 然后用 reward model 给出 $r$
(ii). 单独有个 value model 预测出来 baseline value $v$, 结合 $r$ 通过 GAE 的方法算出来 advantage (记为 A), 然后利用 A 更新 policy model
(iii). 计算 reward 的时候, 计算 reference model 对 reward model 之间的 kl-divengency, 一起写进 $r$ 里面作为 $r$
mathmatically, 最大化如下目标
GRPO 工作流程
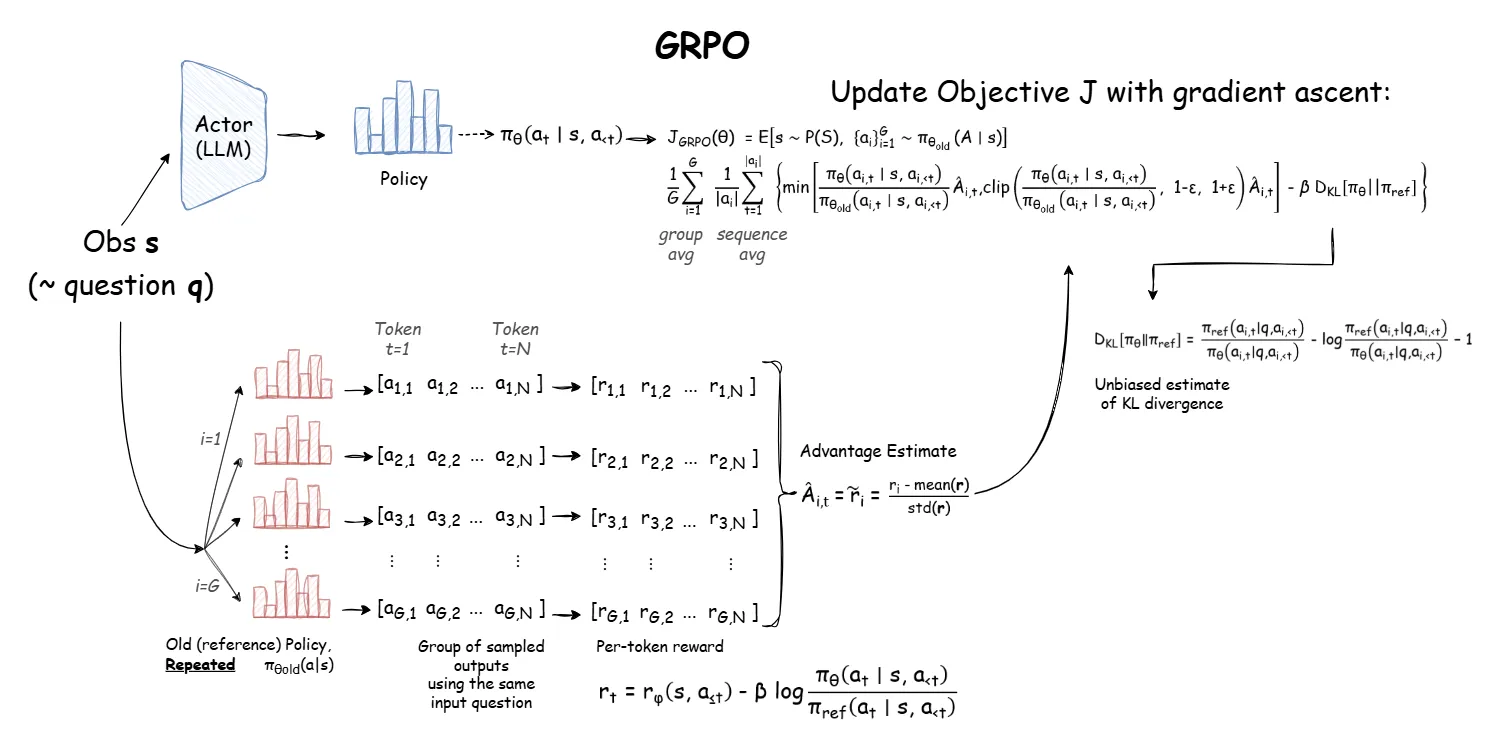
(i). policy model 对单一的 q 采样一系列的 output, 记为 $o_1, o_2,…, o_G$. 对 $o_1, o_2,…, o_G$ 用 reward model 生成对应的一堆 reward, 记为 $r_1, r_2,\ldots,r_G$
(ii). 完全删掉 value model, 组里面计算得到一组 advantage $A_1,A_2,\ldots,A_G$
(iii). policy 和 reference model 的 kl-divergence 直接加到 loss 上面
mathmatically,
这里
GRPO 工作流总结

intuitively,
1.再对比下 PPO v.s. GRPO
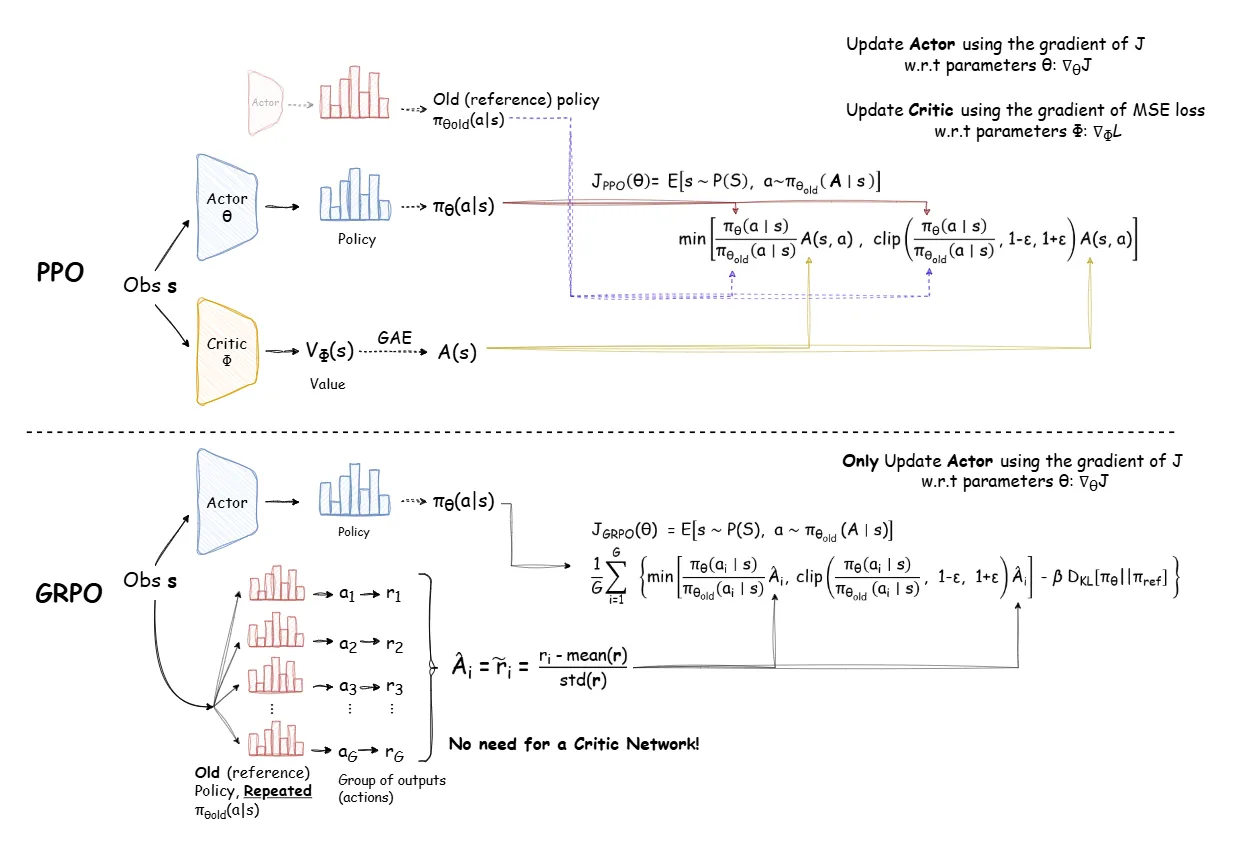
2.GRPO 算是 PPO 简化版吗 ? GRPO 可视为 PPO 的任务导向型简化版,核心在于省略 Critic 模型并通过分组优化提升效率
Reference
[1]. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.
转载请注明来源 goldandrabbit.github.io