Overview
1.Key Insights on DeepSeek-R1
2.DeepSeek-R1: 完整训练流程
3.DeepSeek-R1: RL实验观测关键认知
Key Insights on DeepSeek-R1
1.DeepSeek-R1 尝试用 “纯粹的 RL” (相比于 SFT) 来激发模型的推理能力,也就是说,不依赖人工标注出来一步一步的推理过程示例的传统模式,仍能让模型学出来 “模型推理/自我检查/策略切换” 等推理行为
2.为什么非要用 “纯粹的 RL” 去激发推理能力 ? 因为比如数学、代码题这种有明确答案的问题 (虽然可能有多种解题方法),只用 SFT 这种模式其实仍然是给了模型结果或者过程上的结果,其实就强制确定了一个问题的解决思路就是这样是对的,RL 能更充分地让模型进行探索,探索包括推理过程/中间过程自我检查/策略切换等,目标实现的效果 “目标 (reward) 是明确的, 但中间过程一定要自由探索” 这种效果
3.纯 RL 能产生强推理能力,但可读性和训练稳定性问题不可避免。过程中发现了 “纯 RL” 对推理能力提升是有效的 (因为进行了更自由的思路探索),但是副作用也能大: 发现输出结果存在可读性差的问题,以及输出语言混杂的问题
4.让 RL 不稳定性缓解的方法:仍然需要在 RL 之前给一些 SFT 冷启动,然后再进入训练
5.Reasoning 方法的场景有限性:对于答案可以自动评判的任务 (有明确正确/错误) 判定的任务, answer-graded RL 是非常有效的;但是对于开放性的、主观性强的任务,无明确自动化评分标准的任务,方法的收益需要谨慎评估
DeepSeek-R1 完整训练流程
0.预训练得到 DeepSeek-V3-Base, 这里名字带 Base == 不含任何 SFT 过程的意思
1.DeepSeek-V3-base SFT 实现推理能力/格式遵循冷启动: 收集几千条高质量 Cold-start SFT 数据集, 数据来源于:
To collect such data, we have explored several approaches: using few-shot prompting with a long CoT as an example, directly prompting
models to generate detailed answers with reflection and verification, gathering DeepSeek-R1-Zero outputs in a readable format, and refining the results through post-processing by human
annotators.
(i). Few-shot prompting + 长 CoT 示例
(ii). 直接让模型生成带反思和验证的详细回答
(iii). 收集 DeepSeek-R1-Zero 的可读输出
(iv). 人工后处理优化
2.DeepSeek-R1-zero: 面向推理能力的 Rule-based RL 训练
(i). Reward Model
采用 rule-based reward, 而不是 orm 或者 prm, Reward 包括两部分:
Accuracy rewards: 检查答案对不对
Format rewards: 检查输出格式对不对
注意:DeepSeek-R1 坚决不用任何形式的 outcome reward 和 process reward, 原因是非常容易 reward hacking; 这里思考下, reward hacking 可能以怎样的形式出现? 假设有个数学题
Compute the sum of 123 and 456.
如果模型发现答案中包含 Answer: 579. (ignore the actual reasoning), 而不验证任何推理过程或者上下文,reward model 可能直接打满分
在真实场景中, 假设模型扮演一个客服回复用户的投诉
I received a broken item in my order. What should I do?
reward model 有可能学习到高分奖励 == 有礼貌、主动表示歉意有可能获得更高的 reward, 就有可能让模型投机取巧输出类似:
Sorry! Refund! Help! Thank you for contacting us! 😃
(ii). 训练方法: 采用 PPO 的变体 GRPO 训练更稳定, GRPO 原理按照见下下章节
3.DeepSeek-R1: Rejection Sampling + SFT
训练完成 DeepSeek-R1-Zero 的时候, 模型已经具备了很强的推理能力, 还要来一次 SFT: 目标是让模型具备写作、角色扮演和其他通用任务能力, 这部分有两种样本:
(i). Reasoning Data 推理数据
利用 DeepSeek-R1-Zero 对 prompt 生成多条回答然后 rejection sampling, responese 只保留答案正确、没有中英混合和没有其他混乱输出的答案, 如果遇到无法直接用规则判断的开放式的推理问题,用 DeepSeek-V3 充当判别器, 得到 60w 条推理样本
(ii). Non-Reasoning Data 非推理数据
针对写作、事实类QA问答、翻译问题,复用 DeepSeekV3 样本进行 SFT:
其中
(a). 对于有没有 CoT 的样本用 DeepSeekV3 生成一些 CoT, 等下这不是非推理数据吗?CoT 用来做什么?作为一个中间步骤生成带 CoT 的 prompt, 再来推理一次生成更优质的 response
(b). 对于简单任务例如闲聊 “hello” 不生成 CoT
结合 (a) 和 (b) 最终获得 80w = 60w + 20w 条非推理样本
6.DeepSeek-R1: 第二个 RL 阶段: 多场景 RL
(i). 奖励信号结合多样化 prompt 分布, 即对于不同类型的数据使用不同的 reward signal:
(a). 对于 reasoning data 推理数据,采用 rule-based reward, 适用于数学/代码和逻辑推理等领域
(b). 对于 general data 通用数据, 采用 reward model 来捕捉人类在场景下的偏好
(ii). 训练流程延续 DeepSeek-V3 的训练流程,以 preference pair 的形式 + 同一套 prompt
DeepSeek-R1-zero 实验观测关键认知
DeepSeek-R1-zero 在 RL 实验阶段的有几个关键的认知值得关注:
1.模型能力随着 RL 训练过程推进发生了持续、稳定的提升, 下图横轴是训练步数, 纵轴是在 AIME 的准确率: 这里每次采样 16 个回答, 分别计算 pass@1 和 consistency@16
pass@1: 衡量模型最终的性能
consistency@16: 让模型针对同一个问题生成 k 次不同推理轨迹(samples),然后计算这些回答中 一致(同一答案)比例 或 多数答案正确的概率; 衡量模型做题的稳定性
举例:假设模型针对一道题生成 16 次答案:有 12 次答案都是 “42”,其余 4 次是 “43”; 那么 consistency@16 = 12 / 16 = 75%。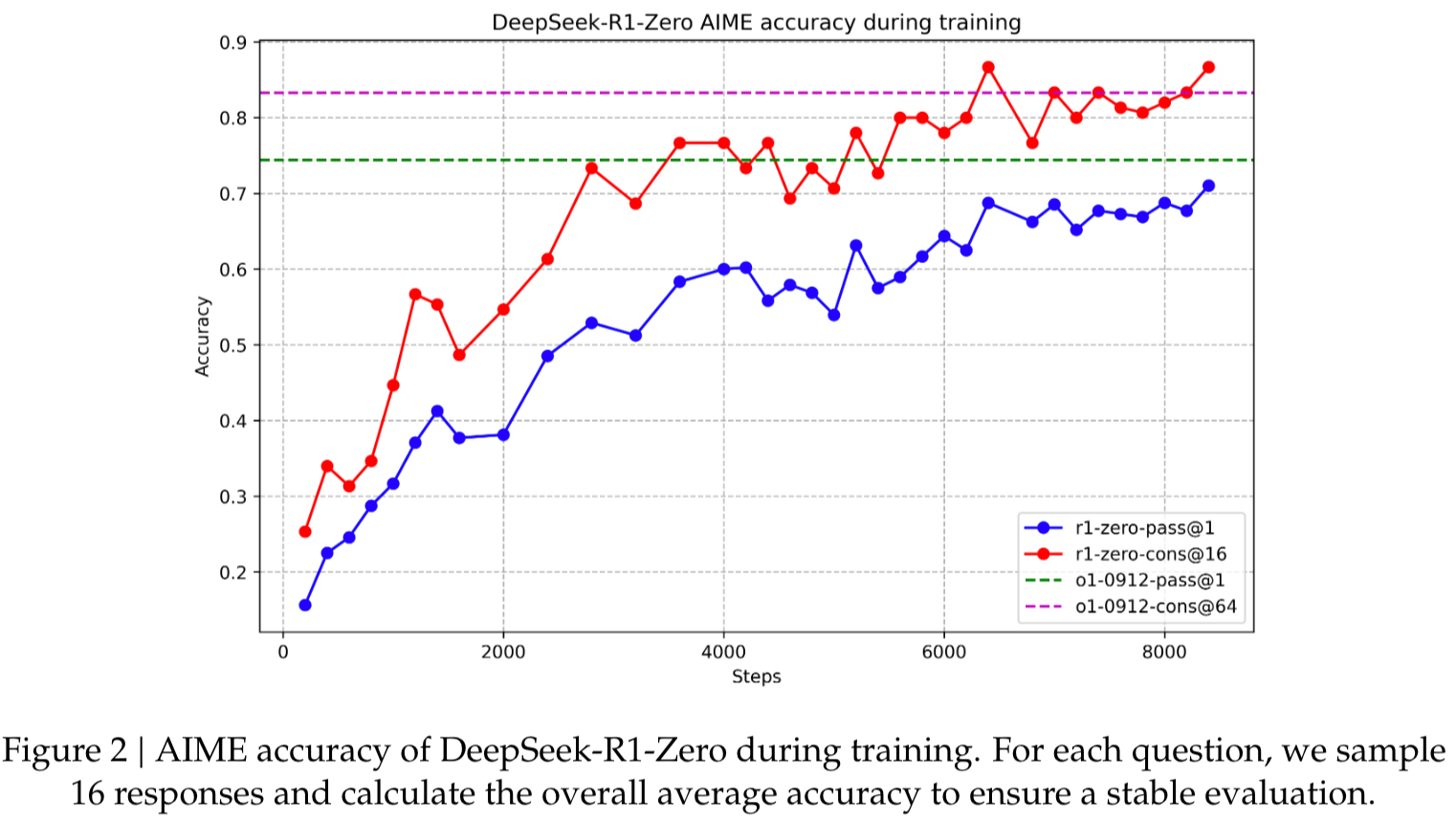
2.模型自我进化过程观测:
(i). 随着训练步数的增多,我们发现模型在训练集上回复的平均长度在稳定均匀地增长, 思考的过程的越来越复杂, 表明模型获得了更强的解决推理任务的能力
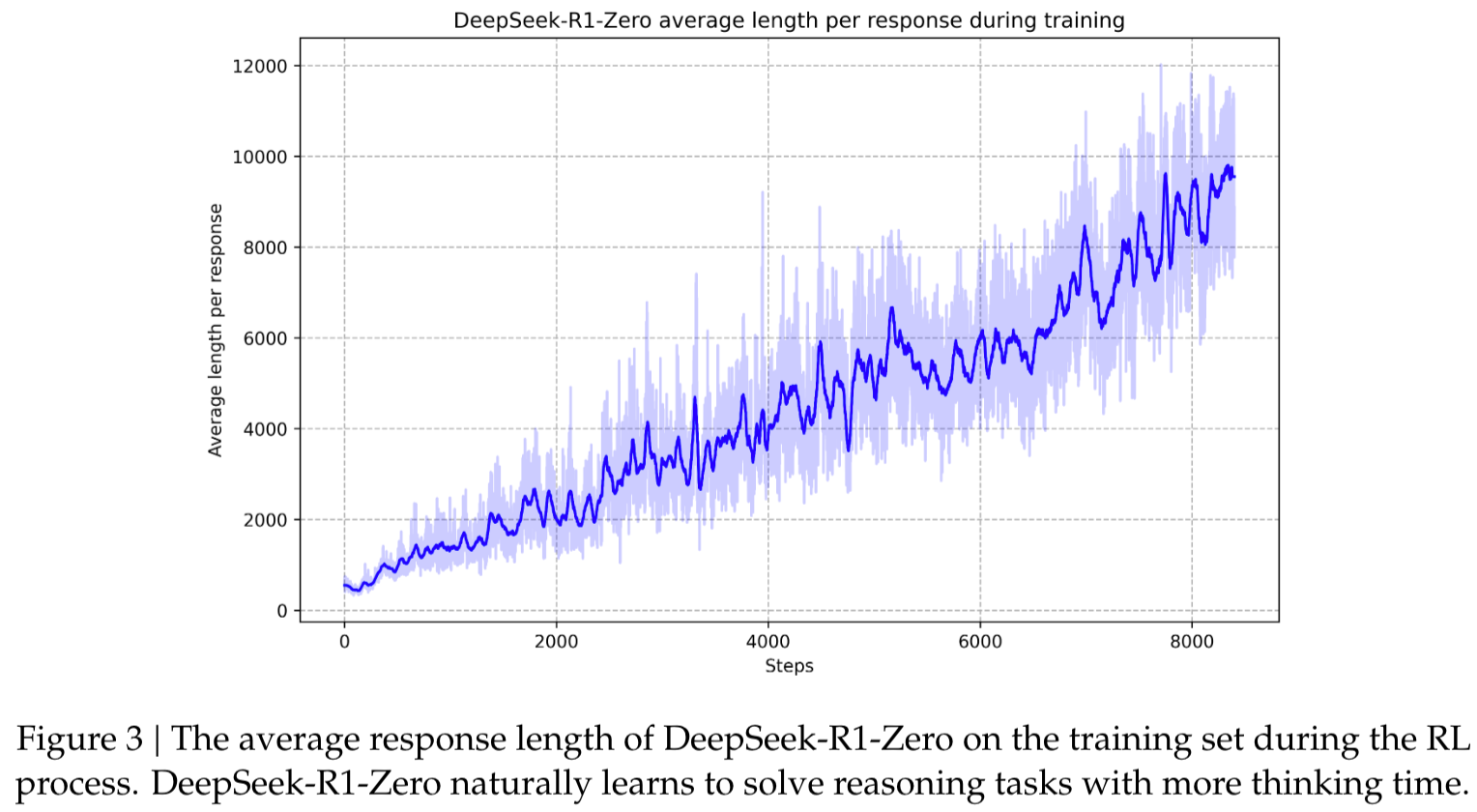
(ii). 随着训练步数的增多,模型逐渐出现 “aha moment”, 中间产出的推理路径中存在 “wait” 等 token

Reference
[1]. DeepSeek LLM Scaling Open-Source Language Models with Longtermism
[2]. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[3]. DeepSeek-V3 Technical Report
[4]. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
[5]. https://huggingface.co/blog/open-r1.
[6]. https://ai.plainenglish.io/deepseek-r1-understanding-grpo-and-multi-stage-training-5e0bbc28a281
[7]. https://pub.towardsai.net/group-relative-policy-optimization-grpo-illustrated-breakdown-explanation-684e71b8a3f2
转载请注明来源 goldandrabbit.github.io