Key Insights On Self-Rewarding LM
1.提出 “Self-Rewarding” 提升 LLM 效果的方式: LLM 自己生产指令 -> 自己评判并生成偏好对 -> 利用自己生产的偏好对学习提升自己的方法
2.验证出来自我奖励是提升 LLM 能力的关键手段之一: 展示了通过语言模型自身生成奖励信号,实现无需人工标注的自我优化的可能性。经过多轮自我奖励训练,模型在多个任务上取得了优异的表现
Self-Rewarding Language Model
整个流程比较 naive: LLM 自己生产指令 -> LLM-as-a-judge 评判并生成偏好对 -> 利用自己生产的偏好对学习提升自己的方法 -> 继续生产新指令 -> xx

intuitively,
1.初始阶段准备一个预训练模型, 先用人标一部种子指令遵循数据, 在种子数据上 SFT 得到对应的模型
2.基于种子指令数据,采用 few-shot 的方式产出一些新的 instruction, 这个过程叫做 self-instruction creation, 例如产生新的 instruction 的 pe 如下:
You are given some task instructions:
1. Translate the following sentence into French.
2. Write a poem about the ocean.
3. Summarize the following paragraph in one sentence.
Your task: Based on these examples, generate a new task instruction that is different but still valid.
产出一些指令, 例如
Write a short story about a mysterious adventure in the mountains.
然后利用 LLM 在新的 instruct 上面生成对应的 answer
3.采用 LLM-as-a-judge 的方法, 给模型的回复进行 0-5 分评分
评分可以选择若干个效果递增的指标, 一个参考 prompt 如下
Review the user's question and the corresponding response using the additive 5-point
scoring system described below. Points are accumulated based on the satisfaction of each
criterion:
- Add 1 point if the response is relevant and provides some information related to
the user's inquiry, even if it is incomplete or contains some irrelevant content.
- Add another point if the response addresses a substantial portion of the user's question,
but does not completely resolve the query or provide a direct answer.
- Award a third point if the response answers the basic elements of the user's question in a
useful way, regardless of whether it seems to have been written by an AI Assistant or if it
has elements typically found in blogs or search results.
- Grant a fourth point if the response is clearly written from an AI Assistant's perspective,
addressing the user's question directly and comprehensively, and is well-organized and
helpful, even if there is slight room for improvement in clarity, conciseness or focus.
- Bestow a fifth point for a response that is impeccably tailored to the user's question
by an AI Assistant, without extraneous information, reflecting expert knowledge, and
demonstrating a high-quality, engaging, and insightful answer.
User: <INSTRUCTION_HERE>
<response><RESPONSE_HERE></response>
After examining the user's instruction and the response:
- Briefly justify your total score, up to 100 words.
- Conclude with the score using the format: "Score: <total points>"
Remember to assess from the AI Assistant perspective, utilizing web search knowledge as
necessary. To evaluate the response in alignment with this additive scoring model, we'll
systematically attribute points based on the outlined criteria.
4.利用生成的打分组 pair, 然后以 DPO 的方式训练模型
实验认知
1.对比 $M_1, M_2, M_3,\cdots$ 指令遵循能力的变化, 对比方式采用 [每一代模型 v.s base 模型比较胜率] 和 [每一代 v.s. 上一代比较胜率] 发现指令遵循能力稳定变强
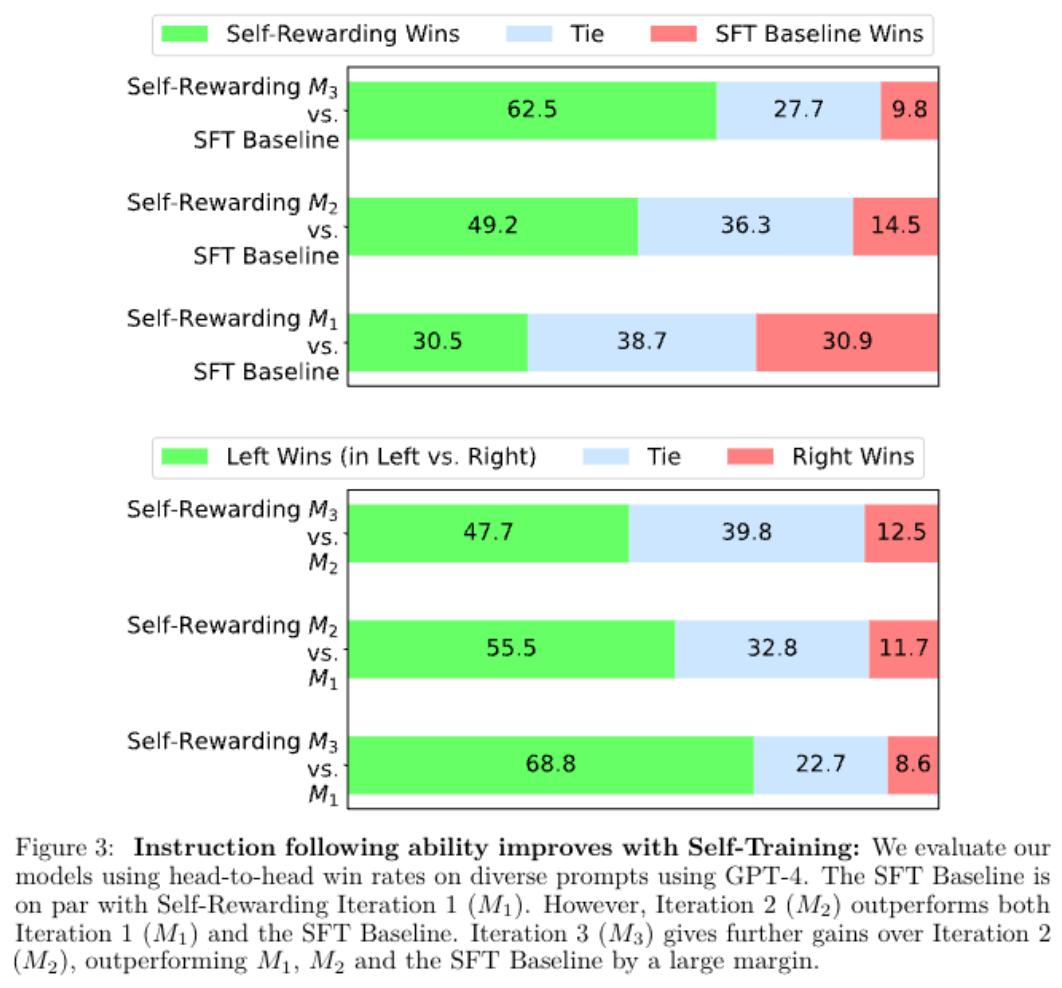
2.这种方法的关键缺陷是什么?
(i). 奖励偏差 (Reward Bias): 模型如果评估能力存在一些偏差,有可能强化 “自认为正确但是事实上不合理” 的行为
(ii). 比较依赖于初始种子任务的质量, 如果初始种子任务的范围是比较有限的,或者质量比较低,生成新的 prompt 也无法保证整个训练数据的多样性
(iii). 实际应用缺乏事实性和安全性约束
Reference
[1]. Self-Rewarding Language Models.
转载请注明来源 goldandrabbit.github.io