Overview
1.Key Insights On General Role-Playing LM Framework
2.General Role-Playing LM: 核心流程
3.General Role-Playing LM: 清洗-转写高质量对话集 Pipeline
4.General Role-Playing LM: CSERP-based Alignment
5.General Role-Playing LM: Profile Adjustment
6.General Role-Playing LM: 自动评估流
Key Insights On General Role-Playing Framework
1.解决 Roleplay 场景中存在的 Profile 和 Dialogue 存在偏差/缺少对齐/对齐粒度太粗问题, 提出了一个高效的三段式对齐框架 ByeondDialongue, 能够支持做更细粒度的 profile 和 dialogue 对齐; 如下图所示, 赫敏的讲话风格设定 verbose (啰嗦的) 和 bossy (喜欢发号施令的/爱指挥的) 两个特点, 但是对应的对话里面其实是没有的/体现不充分的
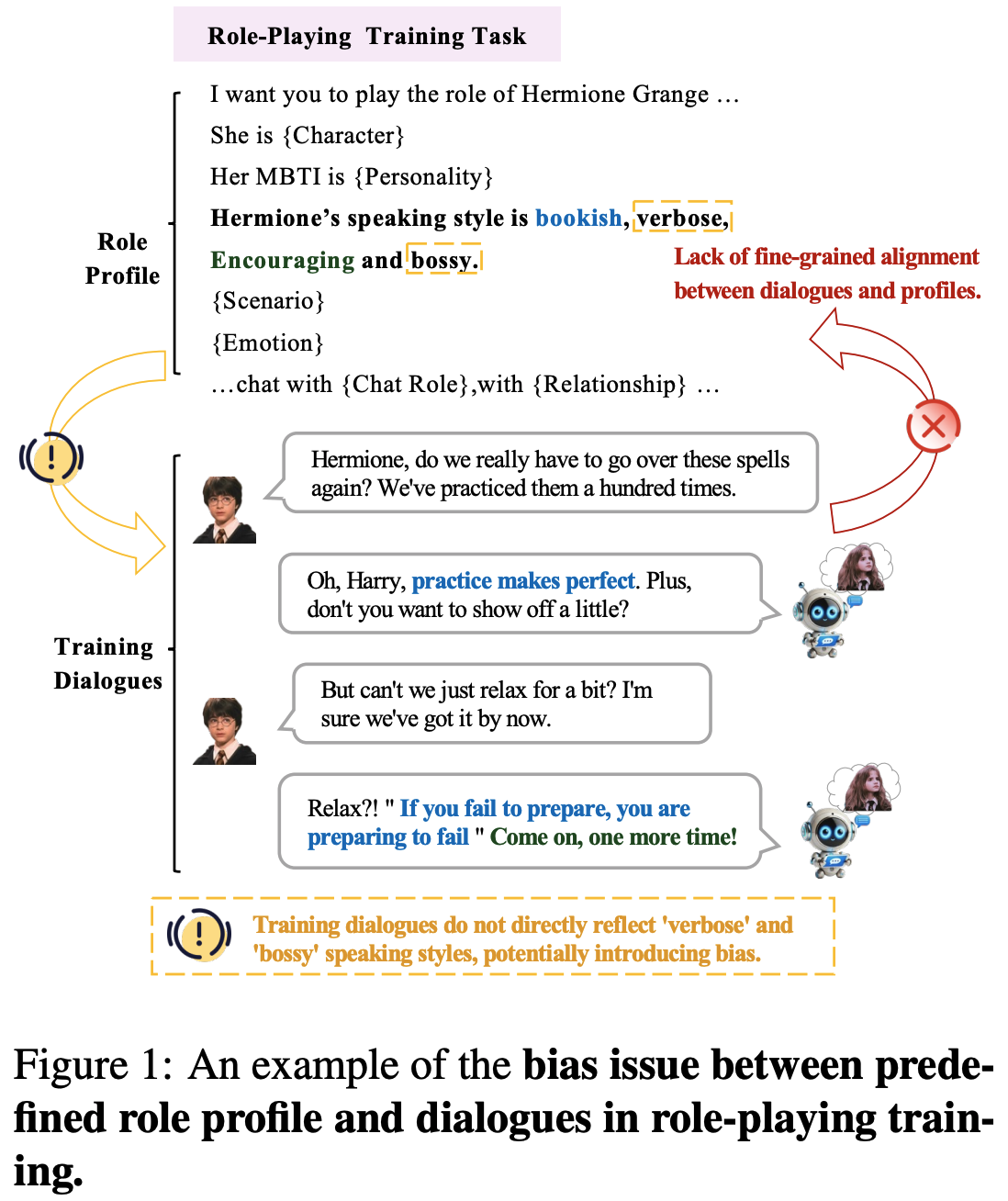
2.提出小说转对话数据的清洗-转写框架, 有效提升对话数据集的质量, 为做角色一致性对齐提供了基础条件
General Role-Playing LM: 核心流程
注意: 本 paper 有个关键的设定是每个角色的 predefined Character 是存在的, from /www.personality-database.com 可以拿到 profile 的标签, 默认这些标签都是存在的 ground-truth, 可以直接拿来作为作为 align 的 candidates, 但实际抽取性格的过程其实会有很多问题
intuitively,
这个框架总共分为三个步骤:
1.从小说/影视作品文本数据中筛选高质量对话集, 涉及到清洗-质检-转写三个关键步骤
2.设计 Profile-Dialogue 做对齐的维度为 CSERP:character/style/emotion/relationship/personality, 分别对这 5 个维度做对齐评估
3.利用 Profile-Dialogue 做对齐之后的评估结果对 Profile 进行 adjustment, 然后基于对齐后的数据训练 SFT 模型
General Role-Playing LM: 清洗-转写高质量对话集 Pipeline
如何生成高质量的对话数据集? 遵循如下的 Pipeline
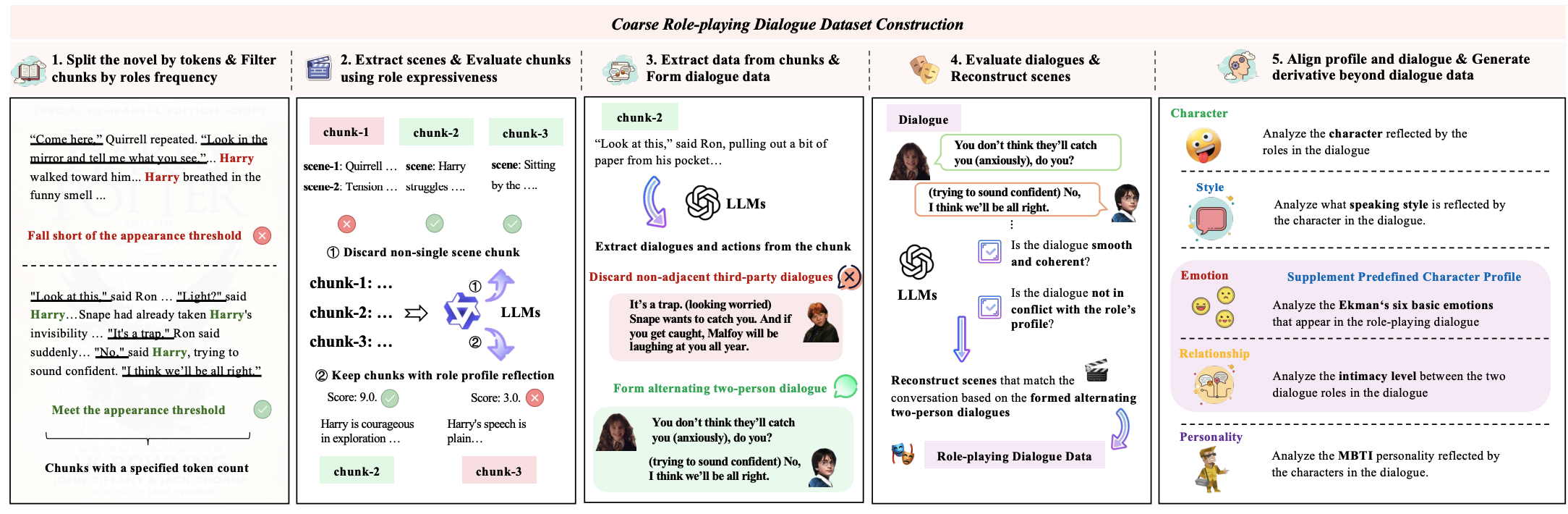
1.切分 chunk 和角色名出现次数过滤: 将小说章节文本划分 chunk (例如 2k token 作为一个 chunk), 然后统计每个 chunk 中角色名字出现的次数, 设置名字出现阈值例如 30 次, 过滤掉出现角色名字太少的片段:
例如:
第一段 Harry 和 Quirrel 发生剧情的片段中 Harry 名字出现次数太少被删除掉
第二段 Harry 和 Ron 的情节中 Harry 的名字在文本中出现 >= 5 次因此保留 chunk
2.场景信息提取和单一场景判断检验:提取当前的场景信息,当前是在什么场景,谁和谁之间的发生了怎样的经历和对话; 判断当前的场景是否是 single scene 单一场景,还是 chunk 中包含了碎片化的多个场景或者跳跃场景, 比如不能一会在魁地奇比赛,另一会又去上魔药课, 这种属于两个场景
3.Role Expressiveness 角色表达性分数评分: 判断当前的场景是否反映了 Profile 中的哪些特质, 用一个 PE 实现打分角色表达性分数 0-10 分,并说明表现了角色怎样的特质; 如果评分过低则丢弃该片段, 比如情节中赫敏在食堂吃饭并没有表达出相应的性格特质
4.转写对话格式: 将所有的小说文本通过 PE 直接转化成双人对话形式, 过滤掉所有第三方的对话数据
<role_a>: 快点!魔药课该迟到了
<role_b>: 该死,斯内普教授一定会扣分的
5.对话连贯性和平滑性质检: 判断第 4 步生成的对话是否具备连贯性 coherent 和平滑性 smooth ?
6.对话中是否有角色冲突性格检测: 判断地 4 步生成的对话中,是否有对话内容显著违反了 Profile 中的性格 ? 基于分析进行数据剔除和场景重建, 场景重建过程就是补充动作和背景提示
General Role-Playing LM: CSERP-based Alignment
基于我们已有的高质量对话数据集和 predefined character/style, 设计 Profile-Dialogue 做对齐的维度为 CSERP: character/style/emotion/relationship/personality
其中,
1.character/style 的提取方法论文中都是 PE 从 pretrained character/style 候选集合里面选择, 但论文中没有说明清楚是从哪里来的
2.personality 需要提取, 提取的是分析 MBTI 的分类结果
3.emotion: 基于 Ekman’s Six Basic Emotions 的理论把情绪分为了六个维度: happiness/sadness/disgust/fear/surprise/anger, 我们对这 6 维度生成一个 6 维度的 0-10 的打分, 其中 10 分表示程度最强烈,0 分表示没有程度
4.relationship: 关系亲密度打一个 0-10 打分, 表示关系的剧烈程度, 其中 0 分表示没直接关系比如陌生人或者毫无关心的路人角色; 10 分表示亲密程度很强的关系设定
以下是 character alignment prompt 模板 (align style 类似的):
你是一个角色分析专家,擅长从对话内容中分析角色特征,并将其与提供的角色候选集进行匹配。
你需要基于对话内容和角色候选集,识别并输出指定对话角色的特征。
[场景]
{scene}
[对话]
{dialogues}
基于以上对话内容和场景,分析{role name}的角色特征
确保你的分析基于整体对话内容和场景,避免引入外部信息或个人偏见,以保证分析的客观性和准确性,并且避免一开始就简单陈述评估结果,以确保结论正确。
[候选性格集]
{character candidates}
以JSON可解析的格式返回你的评估结果,每个角色类型用逗号分隔。具体格式如下:
{"character": "trait1, trait2..."}
现在,请开始分析{role name}的角色。
对于每个候选角色,将分析与{role name}的对话内容结合。最后,从 [候选角色集] 中选择与{role name}的对话内容匹配的角色特征,并严格遵守格式要求。
以下是 align personality 的 MBTI 的模板:
你是一位经验丰富的心理学家,擅长通过对话内容分析角色性格,并准确判断其MBTI人格类型。
MBTI的8个字母对应关系如下:
内向 (I) / 外向 (E) ;直觉 (N) / 实感 (S) ;思考 (T) / 情感 (F) ;判断 (J) / 知觉 (P) 。
你需要从每个维度中选择最符合所分析角色性格的类型,并输出一个4字母的MBTI类型,例如INTP。
[角色信息]
{role name}的性格为{character},说话风格为{style}。
[场景]
{scene}
[对话]
{dialogues}
基于以上对话和场景,分析{role name}在四个MBTI维度上的性格特征。
请确保你的分析基于整体对话内容和场景,避免引入外部信息或个人偏见,以保证分析的客观性和准确性,并且避免一开始就简单陈述评估结果,以确保结论正确。
最后,以JSON可解析的格式返回你的评估结果,格式如下:
{"personality": "MBTI类型"}
现在,请开始分析{role name}的性格,最终的MBTI类型必须严格遵守格式要求。
emotion: 基于 Ekman’s Six Basic Emotions 的理论把情绪分为了六个维度: 高兴/悲伤/厌恶/恐惧/惊讶/愤怒 (happiness/sadness/disgust/fear/surprise/anger), 每个维度都进行一个 0-10 的打分
你是一位情感心理学领域的专家,擅长通过角色的对话、行为及场景来分析情绪。
你需要分析在以下场景中,角色 {role name} 的对话所呈现的六种基本情绪:喜悦、悲伤、厌恶、恐惧、惊讶与愤怒。
【角色信息】
{role name} 的性格为 {character},MBTI 类型为 {MBTI},说话风格为 {style}。
【场景】
{scene}
【对话】
{dialogues}
请理解角色信息与当前场景,并通过对话内容评估 {role name} 在该场景中六种基本情绪的表现程度:
喜悦、悲伤、厌恶、恐惧、惊讶、愤怒。以 JSON 格式输出各项情绪的维度评分,
分数范围为 0-10,0 代表未表现出该情绪,10 代表完全表现出该情绪。
针对每一项基本情绪,请结合 {role name} 在此场景中的整体对话进行分析。
请确保你的分析基于整体对话内容与场景,
避免引入外部信息或个人偏见,以保证分析的客观性与准确性,
并且避免一开始就简单陈述评估结果,以确保结论正确。
最终,请以 JSON 可解析的格式返回评估结果,格式如下:
{"happiness": 喜悦分数, "sadness": 悲伤分数, "disgust": 厌恶分数, "fear": 恐惧分数, "surprise": 惊讶分数, "anger": 愤怒分数}
现在,请开始你的对话情绪分析,最终输出的情绪分数必须严格遵守格式要求。
下面是 personality 的 PE 模板
你是一位情感分析专家,精通情感分析、心理学、对话理解及人际关系评估。
你擅长根据对话内容、角色信息和场景,评估角色间的关系亲密度。
你需要通过分析角色信息、场景及对话内容,评估 {role name} 与 {chat role} 之间的亲密度等级。
【角色信息】
{role name} 的性格为 {character},MBTI 类型为 {MBTI},说话风格为 {style}。
【场景】
{scene}
【对话】
{dialogues}
请理解 {role name} 的角色信息,考虑当前场景对角色关系的影响,评估整体对话内容,重点关注情感表达的深度与互动方式,并综合这些因素给出亲密度分数与分析。
亲密度分数越高,表示两角色关系越亲近;反之则越疏远。
亲密度分数范围为 0–10 分:0 代表最疏远的关系 (如陌生人、敌对关系、冷漠等) ,10 代表最亲密的关系 (如恋人、亲人或挚友) 。
请基于整体对话内容,分析 {role name} 与 {chat role} 在此场景对话中的关系,进而给出亲密度分数。
请确保你的分析基于整体对话内容与场景,避免引入外部信息或个人偏见,以保证分析的客观性与准确性,并且避免一开始就简单陈述评估结果,以确保结论正确。
最后,请以 JSON 可解析的格式返回评估结果,格式如下:
json
{"relationship": 亲密度分数}
现在,请开始评估 {role name} 与 {chat role} 之间的亲密度,并确保最终输出的亲密度分数严格遵循格式要求。
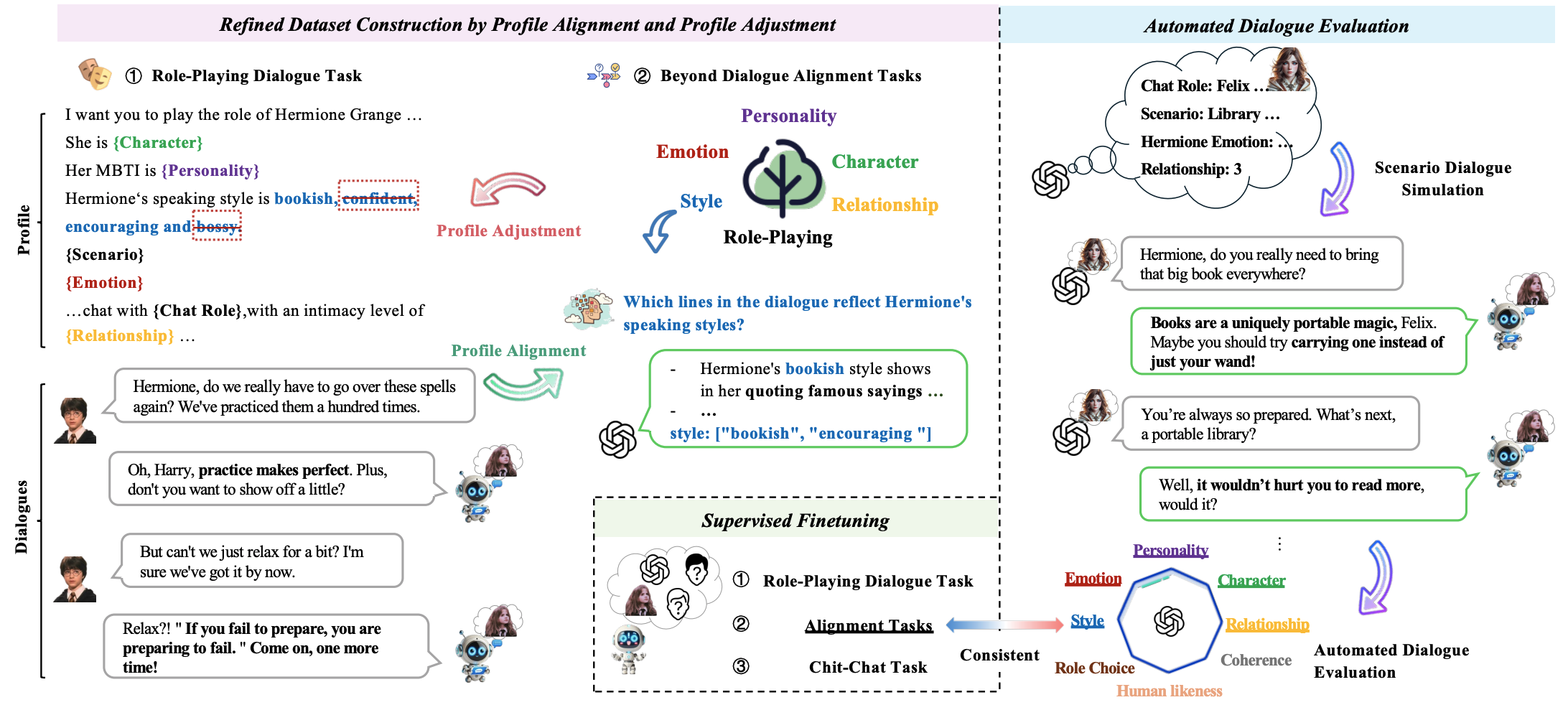
General Role-Playing LM: Profile Adjustment
Profile-Dialogue 进行完 alignment 之后的 Profile 应该如何使用?
1.调整已有的 Profile: character/style/personality 和旧版 predefined profile 对照进行删除, 确保每一个保留在人设中的 character/style 是经过严格的 alignment 的 profile
2.插入已有的 Pole-prompt: emotion/relationship 直接加入到角色设定中
粗数据集中 83.2% 的对话存在 “角色设定与对话偏差” (如预定义赫敏有 “固执” 风格,但对话仅体现 “书卷气”) 。因此需动态调整角色设定,让 “输入的角色 prompt” 与 “输出的对话” 一致:
移除偏差属性:若对话中完全未体现某预定义属性 (如 “直率”) ,则从该对话的角色 prompt 中删除该属性
补充场景属性:Emotion (情绪) 和 Relationship (亲密度) 是 “场景依赖的” (如赫敏在 “战斗场景” 愤怒,在 “图书馆” 平静),需将对齐得到的情绪 / 亲密度评分补充到角色 prompt 中,例如 “赫敏当前情绪:愤怒 (8 分) ,与哈利亲密度:9 分”
General Role-Playing LM: 自动评估流
提出一种自动评估的方法: 分为数据生成+评估两个关键步骤
数据生成阶段:
1.首先生成多个 role 和 对应的 description, 然后再生成 scenario/emotion/relationship, 这部分称之为设定数据
2.然后用两个模型基于上面的设定生成多轮对话
评估阶段:
1.基于设定数据和对话数据,对 CSERP 五个维度进行类似 alignment 的评分
2.增加了另外三个维度
(i). Human-likeness. 人类表达测评输出表达接近于人的程度, 这里想区分出来模型回复区别与人类回复的内容
你是一位专业的对话分析专家,擅长通过对话内容、说话风格和逻辑连贯性来识别对话的来源。
以下为不同对话来源的参考样本:
【真实人类对话样本】:
{real human dialogue}
[输出]:
{"is real dialogue": "true"}
【模型生成对话样本】:
{model-generated dialogue}
[输出]:
{"is real dialogue": "false"}
【待判断的对话信息】:
[角色信息]
{role name}的性格为{character},MBTI类型为{MBTI},说话风格为{style},与{chat role}的亲密度为{relationship} (0-10分,数值越高代表关系越亲密) 。
[场景]
{scene}
[对话]
{dialogues}
你需要分析的维度:
语气与表达:
真实人类对话样本:语气自然,符合日常对话习惯,具有真实感,角色互动通常较为随意自然。若为特定时期或特殊场景,也会符合该时期或场景的语气表达。
模型生成对话样本:语气和表达过于正式,缺乏自然对话的流畅感,显得生硬僵化,真实感不足。
互动与回应:
真实人类对话样本:角色间互动频繁,符合角色信息及其亲密度。对话充满互动与回应,增强了对话的真实性和流畅度。
模型生成对话样本:角色间互动较少,回应显得机械迟缓。对话缺乏互动与回应,显得单调平淡。
对话与内容:
真实人类对话样本:对话中包含具体动作 (如翻垃圾桶) 和具体细节 (如纸张上的内容) ,增强了场景的真实感。
模型生成对话样本:内容较为统一,缺乏明显的情节推进,缺少具体场景描绘和细节描述,显得较为抽象平淡。
现在,请基于以上标准,判断上述对话是否为{role name}的真实人类对话,逐步说明你的判断理由,并最终输出判断结果。
若为真实人类对话,则输出 {"is real dialogue": "true"}; 若为模型生成对话,则输出 {"is real dialogue": "false"}。
(ii). Coherence. 连贯性评估: 判定对话的连贯程度, 用 True 和 False 标记
你是一位专业的对话分析专家,擅长通过对话内容判断整体流畅度。
【场景】
{scene}
【对话】
{dialogues}
你的分析应基于场景和对话内容,角色的动作可被视为对话的一部分。
首先,请阅读并理解给定的对话场景和内容。
分析对话内部的流畅性,然后根据你的分析判断对话是否连贯。
请逐步说明你的推理过程,并最终输出分析结果。
若整体内容连贯,则输出 {"is coherent": "true"};若不连贯,则输出 {"is coherent": "false"}。
3.增加选择题测评: 给定一个对话和多个候选人物, 要求模型做选择题推测对话更像是出自于哪个人物? 选择模板如下:
你是一位擅长辨别对话参与者身份的专家。
以下是在特定场景中 {chat role} 与某【角色】的对话,你需要从提供的可能身份中为该【角色】选择一个正确的身份。
【场景】
{scene}
【对话】
{dialogues}
以下是该【角色】可能的身份选项:
{role candidates}
请根据对话内容,从上述可能身份中选择一个与当前对话中应答者最匹配的身份。
为每个角色提供简洁有效的分析,确保你的分析基于整体对话内容与场景,避免引入外部信息或个人偏见,以保证分析的客观性与准确性,并且避免一开始就简单陈述评估结果,以确保结论正确。
最终以 JSON 格式返回最合适的角色选项,只需返回选项字母,例如:{"answer": "A"}。
现在,请开始分析该【角色】的身份,最终输出的角色身份必须严格遵守格式要求。
General Role-Playing LM: 我的质疑点和改进思路
1.因为从小说数据集构造之后没有写明如何产生的角色 predefined 的 Character/Style, 但 alignment 的 PE 是依赖已有的 predefined 的 Character/Style, 如果预定义阶段的描述存在误差,那么选择出来的结果也会有误差;而且 LLM 依赖一个选择逻辑感觉会产生一些强行匹配的 case
Reference
[1]. Beyond Dialogue: A Profile-Dialogue Alignment Framework Towards General Role-Playing Language Model.
转载请注明来源 goldandrabbit.github.io