Overview
- Parallel Training 并行训练
- Data Parrallel 数据并行
- Pipeline Parrallel 流水线并行
- Tensor Parrallel 张量并行
- 3D Parrallel 混合并行策略
Parallel Training 并行训练
- 为什么需要并行训练模型? 期望利用多块 GPU 提升训练效率,需要有对应的并行训练策略最大化训练效率,一方面提升大数据量下的效率,另一方面提升更大模型结构下的训练效率
- 并行训练分常见分为三种并行的模式:数据并行、流水线并行、张量并行
Data Parrallel 数据并行
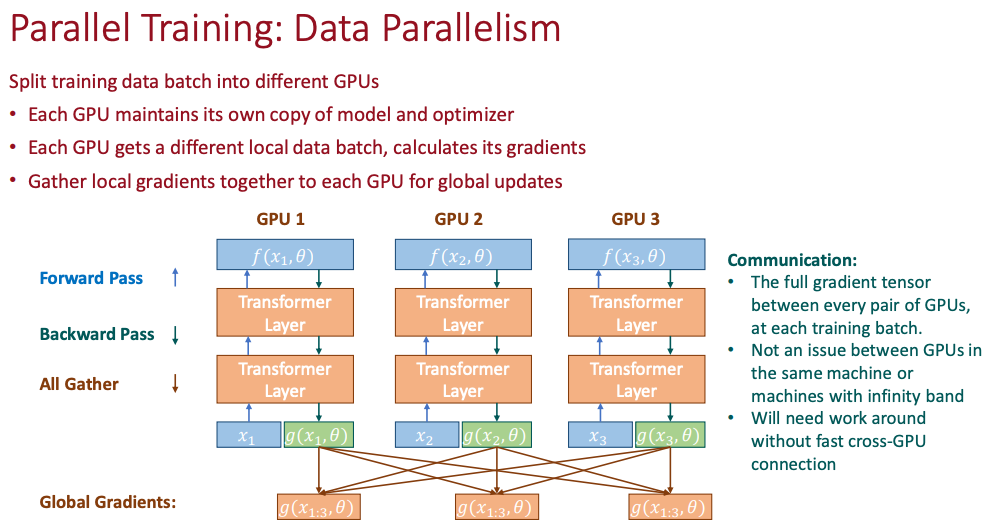
- 数据并行的思想比较简单: 当我们有多块 GPU 的时候,数据并行是在训练阶段将所有的模型参数和优化器/激活函数都要复制到每一块 GPU 上, 并各自维护一份对应 Local 参数, 这个 Local 参数在多次迭代中会多次被 Global 参数更新
- 梯度汇总: 每个 GPU 计算出来本地的梯度之后,需要和其他的 GPU 通信并且汇总梯度,最简单的汇总就是平均或者求和
- 汇总完成后,更新本地参数,使得每个 GPU 上的模型保持同步
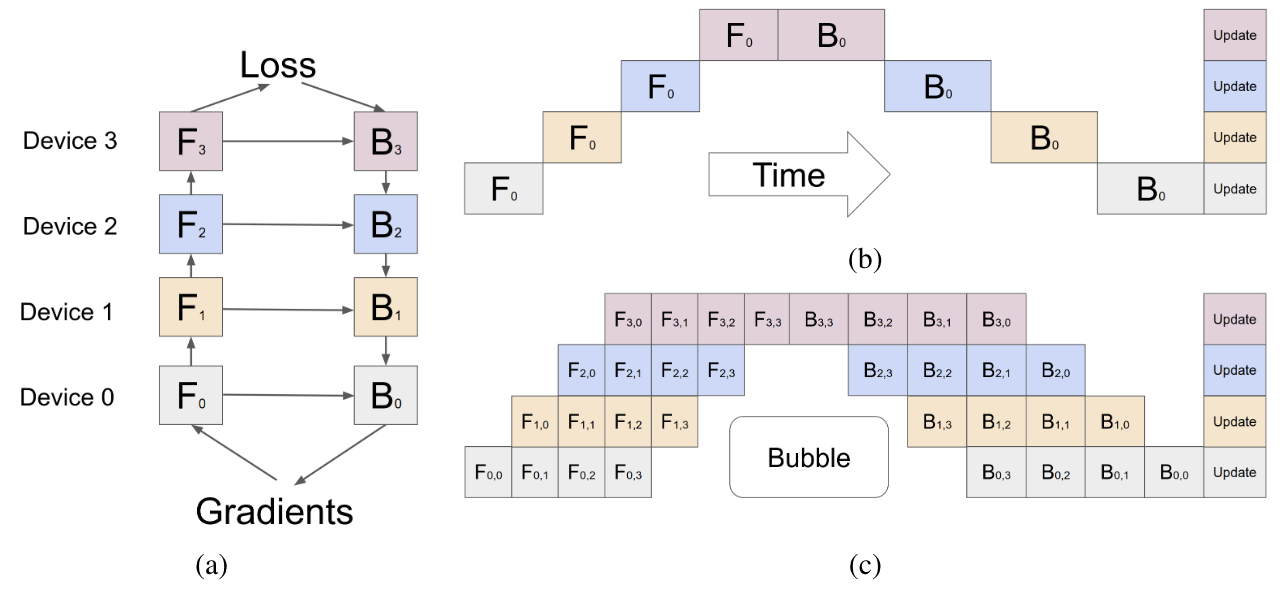
Pipeline Parrallel 流水线并行
- pipeline parrallel 的核心思想: 模型的层就是一个天然的流水线结构,想要并行一个最直观的想法是把模型按照层来切,假设我们有 6 层 Transformer Layer 结构, 我们就把不同的层的参数维护在不同的 GPU 上,如果有 6 个 GPU,那么我们各放一个
Layer1 → Layer2 → Layer3 → Layer4 → Layer5 → Layer6
假设我们有 3 张 GPU,做流水线并行:
GPU0: Layer1、Layer2
GPU1: Layer3、Layer4
GPU2: Layer5、Layer6
按照流水线并行的思想,每个时间步处理如下
| 时间步 | GPU0 | GPU1 | GPU2 |
|---|---|---|---|
| t1 | Layer1(x1) | idle | idle |
| t2 | Layer2(x1) | Layer3(x1) | idle |
| t3 | Layer1(x2) | Layer4(x1) | Layer5(x1) |
| t4 | Layer2(x2) | Layer3(x2) | Layer6(x1) |
| t5 | Layer1(x3) | Layer4(x2) | Layer5(x2) |
| t6 | Layer2(x3) | Layer3(x3) | Layer6(x2) |
| … | … | … | … |
- 流水线并行的优势:并行思想简单且和网络结构没有关系,每一个网络都有多个层组成
- 流水线并行的关键问题:
- 空转导致的 Bubble 浪费,当我们有更多的 GPU 的时候,浪费会更严重;具体来说 K 个 GPU,气泡占比时间是 $\frac{K-1}/{K}$, 每个 GPU 都要等上一个; 分子就是上面图片中空白的地方
- 为了解决这个 Bubble 浪费的问题,我们可以把一个 mini-batch 划分成 M 个 micro-batch,然后再依次通过多个 GPU 训练,当我们划分 M 个 mini-batch 的时候,气泡占比时间 $\frac{K-1}/{K+M-1}$,实验表明,当 $M\ge 4K$ 的时候,气泡产生的空转时间对训练时长影响非常轻微
Tensor Parrallel 张量并行
- 张量并行的思想: 把同一个层 (本质上就是各种张量) 切成到不同的 GPU 上,然后通过各种并行矩阵运算操作实现并行
- 张量并行的优势: 完全没有 bubble
- 张量并行的在 MLP 和 Self-Attention 的两类方法
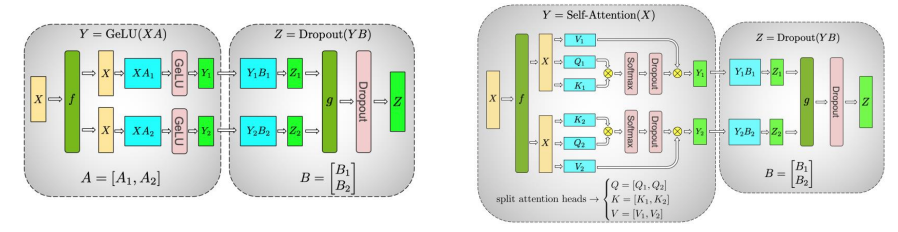
- 张量并行,分为列拆分和行拆分, 我们直接用一个具体数值输入来完整模拟 Column Parallel 和 Row Parallel 的计算流程, 设定:
# 输入向量
x = [1, 2, 3, 4, 5, 6]
# 权重矩阵 W(4×6),数值如下
W = [[1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 1],
[1, 1, 0, 0, 1, 1],
[0, 0, 1, 1, 0, 0]]
Column Parallel 列拆分: 列拆分中,输入数据也必须按照列拆分, 最后计算 all-reduce
W0 = [[1,0,1], W1 = [[0,1,0],
[0,1,0], [1,0,1],
[1,1,0], [0,0,1],
[0,0,1]] [1,1,0]]
x0 = [1,2,3] # GPU0
x1 = [4,5,6] # GPU1
y0 = x0 * W0ᵀ
y0 = [4, 2, 3, 3]
y1 = [5, 10, 6, 9]
# All-Reduce 求和版本
y = y0 + y1 = [4+5, 2+10, 3+6, 3+9] = [9, 12, 9, 12]
Row Parallel 行拆分: 行拆分中,输入数据无需拆分, 最后执行 All-Gather 拼接
W0 = [[1,0,1,0,1,0],
[0,1,0,1,0,1]] # GPU0
W1 = [[1,1,0,0,1,1],
[0,0,1,1,0,0]] # GPU1
y0 = x * W0ᵀ
y0 = [9,12]
y1 = [14,7]
y = [y0, y1] = [9,12,14,7]
- 什么时候列拆分,什么时候行拆分? 输入层很宽列拆分,投影层使用行拆分; 假设
假设这里输入 x 很宽(例如 4096→16384)使用 Column Parallel(列拆分):把权重按列切,让每个 GPU 只处理输入的一部分,然后 All-Reduce 求和, 目的是减轻每个 GPU 的计算负载,因为输入特征太多; Linear2(投影层):hidden_dim → out_dim; 这里输出 y 比较小(例如 16384→4096);使用 Row Parallel(行拆分):把权重按行切,每个 GPU 计算输出的一部分,然后 All-Gather 拼接; 目的是让输出分块直接拼接,减少通信量FFN: x -> Linear1 -> GELU -> Linear2 -> y
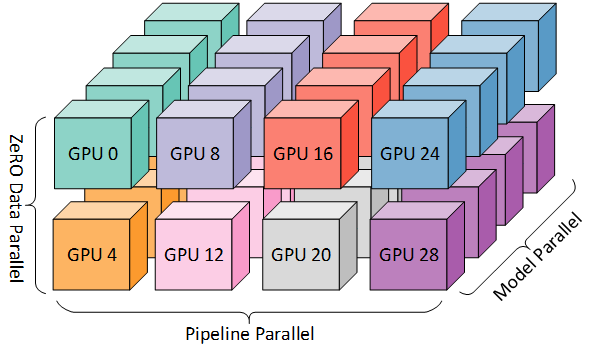
3D Parrallel 混合并行策略
以上 3 种方法并行使用成为标注的并行范式, 也叫 3D 并行
Reference
[1]. Parallel Training
转载请注明来源 goldandrabbit.github.io