
Overview
1.LLaMA
2.LLaMA2 和 LLaMA-2-Chat
3.LLaMA3
LLaMA
参数量: 7B/13B/33B/65B
上下文长度: 2K
数据集大小: 1.4 Trillion token
LLaMA 预训练数据
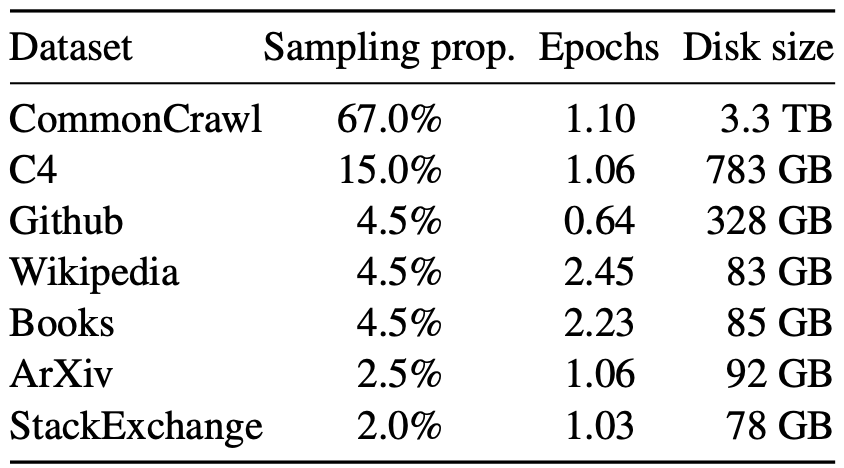
exhuasively,
1.English CommonCrawl: 英文爬虫数据, 占比高达 67%, 绝对的大头数据, 训练了 1.10 个 epoch
2.C4: 探索实验的时候, 发现使用不同预处理的方法后的 CommonCrawl 可以提高性能.
3.Github: 基于 Google BigQuery 得到的 Github 数据, 只用了 Apache/BSD/MIT licenses 的数据. 采用两种规则过滤: 利用每行的长度和数字字母的比例干掉有杂质的数据, 用正则表达式过滤掉 header 之类的信息. 最后再做文件级别的去重操作.
4.Wikipedia: 维基百科, 高质量的数据, 占比 4.5%, 训练了 2.45 个 epoch. 覆盖 20 种语言. 删掉了各种链接, 评论和其他的 boilerplate
5.Books: 包括两个数据集: Gutenberg 和 Book3
6.ArXiv: 学术论文, 高质量数据, 占比 4.5%, 训练 1 个 epoch
7.StackExchange: 高质量的问答数据
LLaMA Tokenizer
1.Tokenizer 采用 byte-pair encoding algorithm (BPE) 采用 Sentence-Piece 实现
2.所有数字 split 成 individual digits
3.未知的 UTF-8 字符用 byte 表示
4.词表大小 32K
LLaMA Arichitecture
基于 transformer decoder-only 主架构上, 上做了如下的改进
Pre-normalization: RMSNorm normalizing
1.相比原始的 transformer 架构, 采用了 pre-normalization 的方式: 也就是说在 input 之后先过 layer-norm 再 attention, 而不是传统方法上的先 attention 再 layer-norm
2.将 pre-normalization 的方式从原始的 layer-normalization 转化成了 RMSNorm
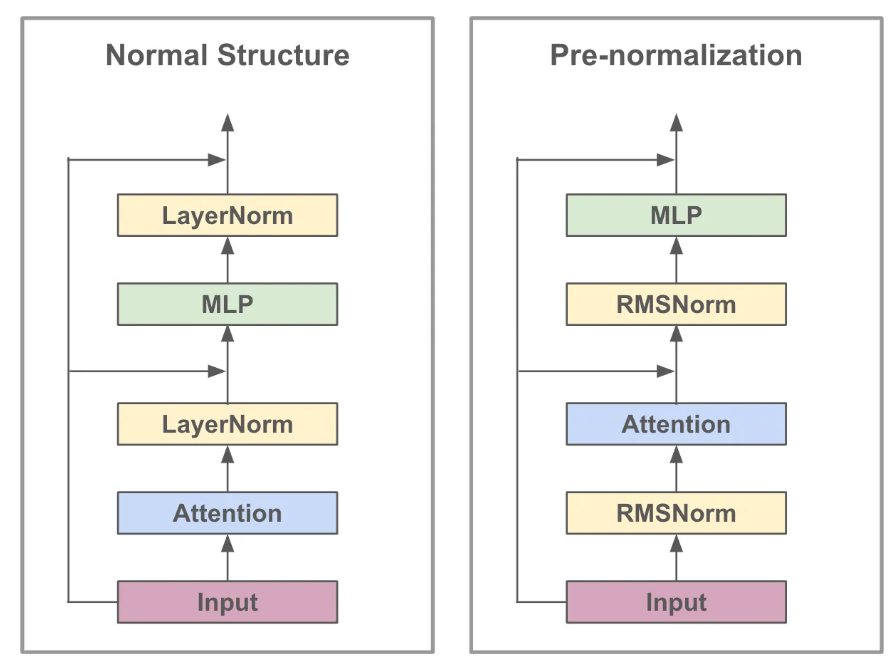
RMSNorm 是一种简化版本的的 LayerNorm, 相比原始的 LayerNorm, RMS 稳定性和泛化性都更好, 效率提升了 10-50% (有这么强吗?)
RMSNorm 是 Root Mean Square Normalization Layer 均方根正则化层, 计算公式如下
SwiGLU activation function
SwiGLU 是一个激活函数, 用来取代标准的 ReLU
RoPE 旋转位置编码
训练参数
Opitimizer
AadamW
beta_1 = 0.9
beta_2 = 0.95
weight decay = 0.1
gradient clip = 1.0
warmup_step = 2000
LLaMA2
LLaMA2 是 LLaMA 升级版本, 同时 LLaMA2 基础上 finetune 了一个 LLaMA2-Chat 用于对话场景.
参数量: 7B/13B/70B, 还有个 34B 版本未公布
上下文长度: 4K (+100%)
数据集大小: 2.0 Trillion token (+40%)
LLaMA1 v.s. LLaMA2 宏观对比
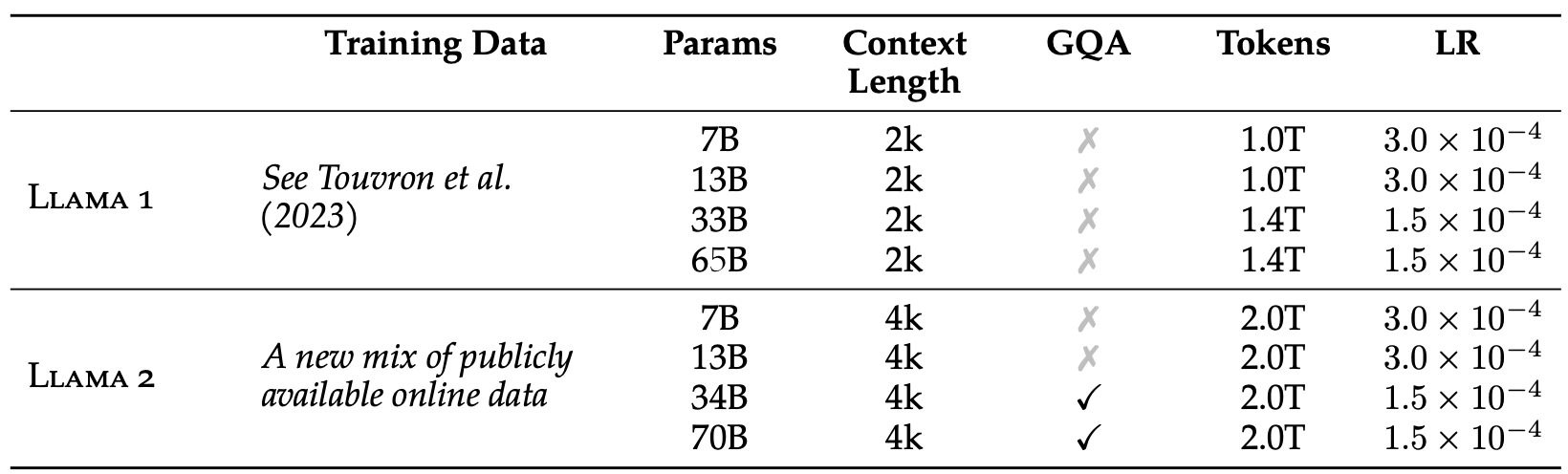
LLaMA2 预训练数据
LLaMA-2 adopts a new mixture of pre-training data (i.e., sources that are known to be high-quality and factual are sampled more heavily) and increases the size of the pre-training dataset by 40%.
intuitively,
1.采用了新的混合数据, 数据质量是显著很高的, 且事实类的数据被更大量的采样, 相比 LLaMA1 数据增加了 40%, 不得不说 效果都靠堆砌数据啊
LLaMA2 Tokenizer
1.Tokenizer 采用 byte-pair encoding algorithm (BPE) 采用 Sentence-Piece 实现
2.所有数字 split 成 individual digits
3.未知的 UTF-8 字符用 byte 表示
4.词表大小 32K
LLaMA2 Architecture
LLaMA2 核心改动是采用了 Grouped-Query Attention (GQA)
Grouped-Query Attention (GQA)
其实是原始的 multi-head self attention 和 multi-query attention 的一个折中选择
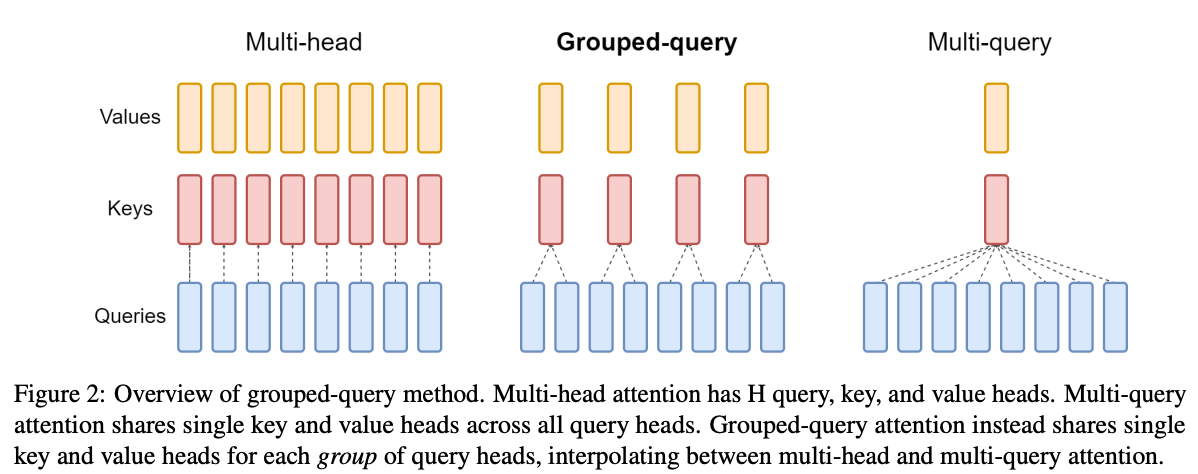
将总共 N 个 self-attention head 分成了几个组, 每个组里面用一个
思考: 这个 Group_num 怎么调优呢?
LLaMA-2-Chat
有了 LLaMA2 之后, SFT + RLHF 搞出来 LLaMA-2-Chat
LLaMA3
参数量: 8B/70B/405B
上下文长度: 128K (显著增大)
数据集大小: 15 Trillion tokens (显著增大)
LLaMA3 预训练数据
Meta 自己构建一个数据集, 并做了大量的洗数据操作:
PII and safety filtering personally identifiable information
过滤掉个人身份信息
Text extraction and cleaning
原生 HTML 数据清理
De-duplication 去重操作的 3 个层级
1.URL-level de-duplication
2.Document-level de-duplication: 采用的是 MinHash算法
3.Line-level de-duplication: 行级别去重, 采用 ccNet, 在每 3000 万 doc 中移除出现超过 6 次的行
Heuristic filtering
启发式过滤低质量文档或者重复太多的文档
1.计算重复 n-gram 覆盖率比例, 来干掉日志记录或者错误消息组成的行, 这种就是很长很独特但没有意义的东西
2.使用 “dirty word” 计数这种启发式规则过滤成人网站
基于模型的质量过滤
1.用 fasttext 训练一个是否被维基百科引用的分类器
2.基于 LLaMa2 预训练计算一个 Roberta 分类器
多语言数据
1.使用 fasttext 将文档分成 176 中语言
确定数据比例
为了构建高质量的数据集, 必须确定预训练数据中不同数据源的比例
1.首先训练一个知识类别分类器, 对 web 上出现太多的类别进行采样减少
2.怎么确定最优的比例 ? 在一个数据比例上训练几个小模型, 并使用这些数据比例来预测大模型的性能. 然后搞几个不同的比例, 对比不同数据比例上的效果, 然后重复这个过程, 确定比例候选, 然后再这个比例上选一个更大的模型, 评估该模型在几个关键基准上的表现
3.数据比例总结: 50% 常识 token, 25% 数学和推理 token, 17% 的代码 token, 8% 的多语言 token
LLaMa3 Architecture
LLaMa3 在架构上有 4 个核心优化
1.Group query attention: 延续 GQA, 采用 8 个 k-v heads 来提升 inference 效率
2.Attention Mask: 采用了一种 attention mask 方式, 目的是为了避免出现这样一种情况: 对同一个序列, 在不同 doc 之间的 self-attention 是不同的; 发现在标准预训练的过程中, 这个操作没什么影响, 但是在对超长序列预训练的时候, 这个很重要
3.采用了个 128K token 的词表, 其中有 100K 来自于 tiktoken tokenizer, 28K 来自于非英语语种
4.调整了 RoPE 的一个超参数: base frequency hyperparameter 到 50K, 目的是能支持更长的上下文, 有文献曾经说明最长支持 32768 的长度
Now My Perspective
1.相比 OpenAI 那种 Closed AI, 这是真 OpenAI
Reference
[1]. LLaMA: Open and Efficient Foundation Language Models.
[2]. LLaMA-1 技术详解. https://zhuanlan.zhihu.com/p/648774481
[3]. LLaMA 2: Open Foundation and Fine-Tuned Chat Models.
[4]. LLaMA 超详细解读(paper & code). https://zhuanlan.zhihu.com/p/632102048.
[5]. LLaMA-2 from the Ground Up. https://cameronrwolfe.substack.com/p/LLaMA-2-from-the-ground-up
[6]. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.
[7]. Root Mean Square Layer Normalization.
[8]. The Llama 3 Herd of Models. https://arxiv.org/pdf/2407.21783
[9]. Llama 3.1技术报告(精华版). https://zhuanlan.zhihu.com/p/712251536
转载请注明来源 goldandrabbit.github.io