Overview
1.Recap Transformer
2.decoder-only 架构
3.为什么要用 decoder-only 的架构 ?
Recap Transformer
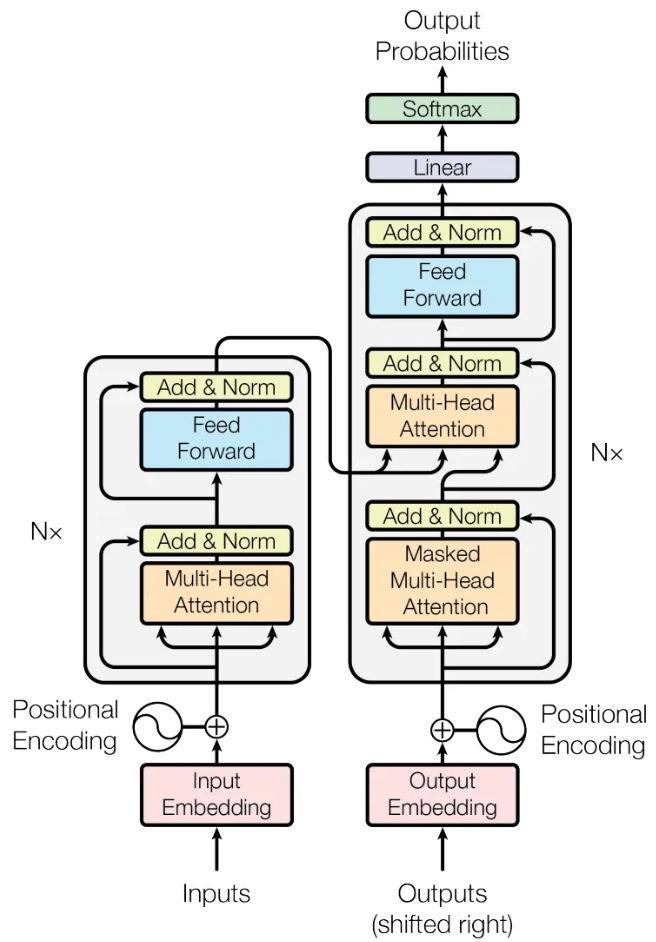
采用 encoder-decoder 结构如下图
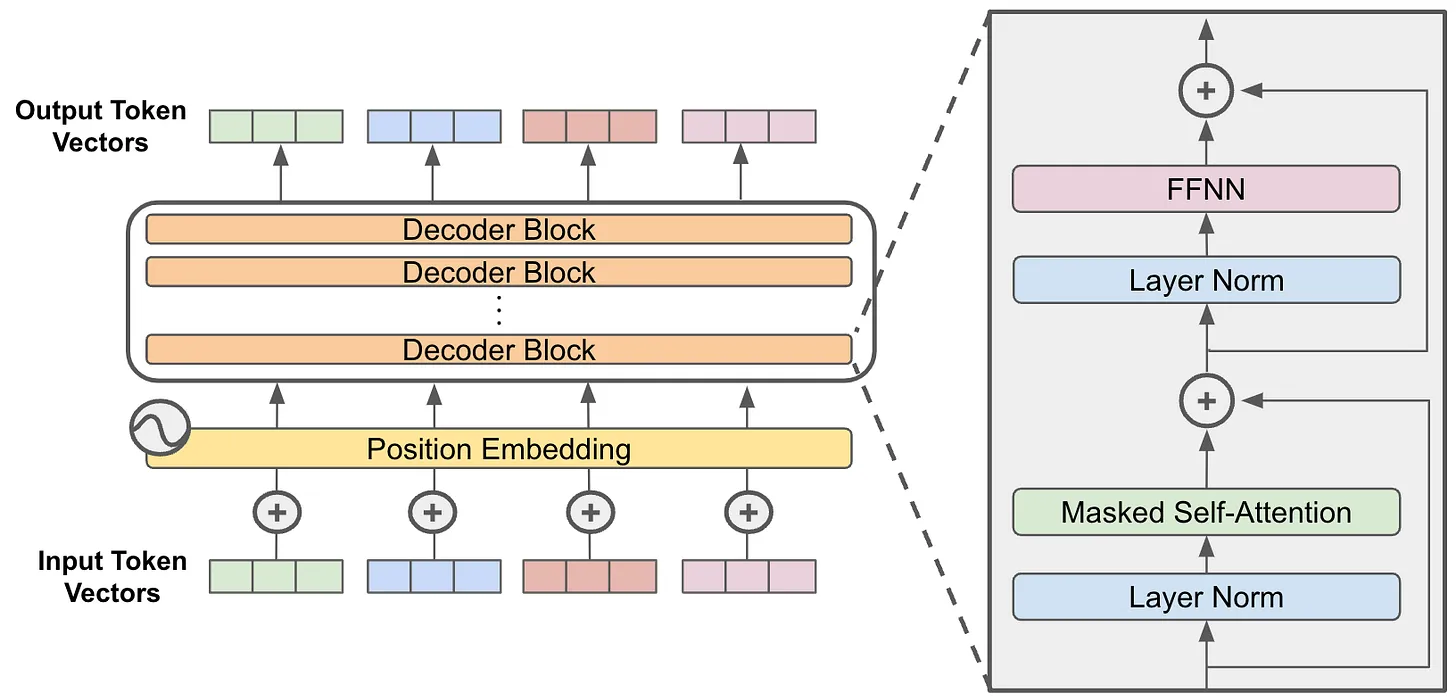
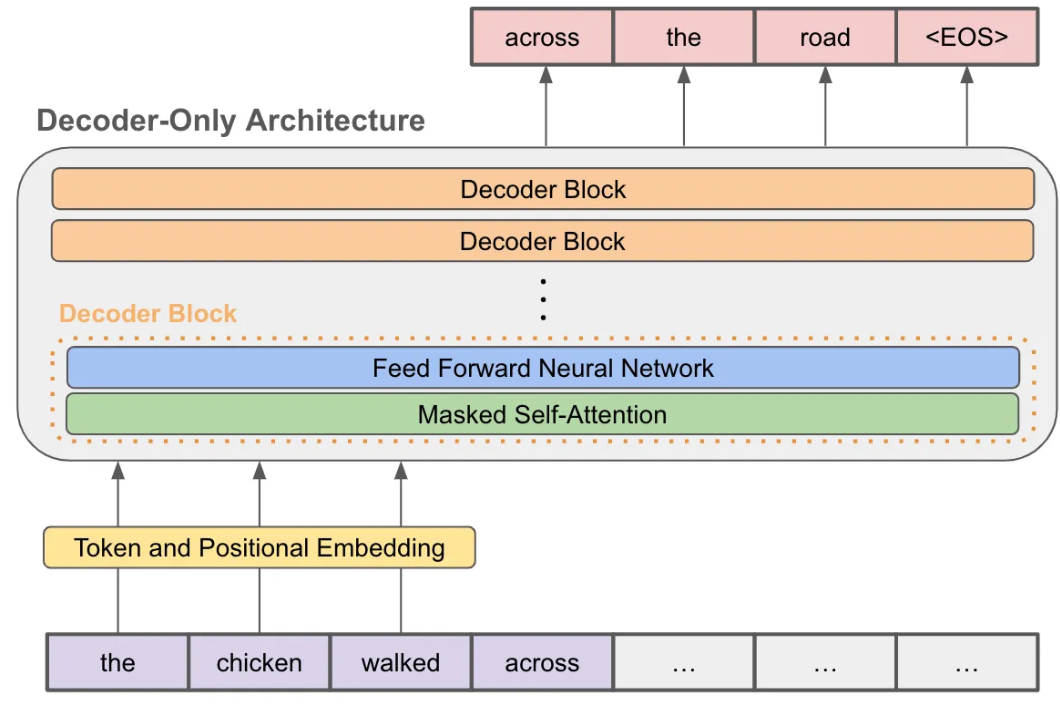
decoder-only 架构
相比最原始的 encoder-decoder Transformer 架构, decoder-only 把 encoder 这边全部删除 (连带着 encoder-decoder self attention 的连线模块), 可以理解为是多个 decoder block 堆叠组成的, 其中最基础的 decoder-block 的组成就是 masked self-attention 上面跟一个 FFN 层
为什么要用 decoder-only 的架构 ?
理解这个问题有几个理解层次
1.首先思考用的为什么是 decoder 结构, 而不是 encoder 结构? 换句话说 encoder-only 不行吗 ?
why the decoder? The choice of using the decoder architecture (as opposed to the encoder) for LMs is not arbitrary. The masked self-attention layers within the decoder ensure that the model cannot look forward in a sequence when crafting a token’s representation. In contrast, bidirectional self-attention (as used in the encoder) allows each token’s representation to be adapted based on all other tokens within a sequence.
Masked self-attention is required for language modeling because we should not be able to look forward in the sentence while predicting the next token. Using masked self-attention yields an autoregressive architecture (i.e., meaning that the model’s output at time t is used as input at time t+1) that can continually predict the next token in a sequence.
intuitively,
1.解码器中的 mask self-attention 确保模型在学习 token 的表示时不能向前偷看序列, 因为我们采用的是 autoregressive 的架构, 即 t 时刻的输出用在了 t +1 时刻的输入里; 如果要用 encoder 里面的双向的 self-attention 的结构, 就是那就允许 token 学习的时候看到前后序列所有的信息
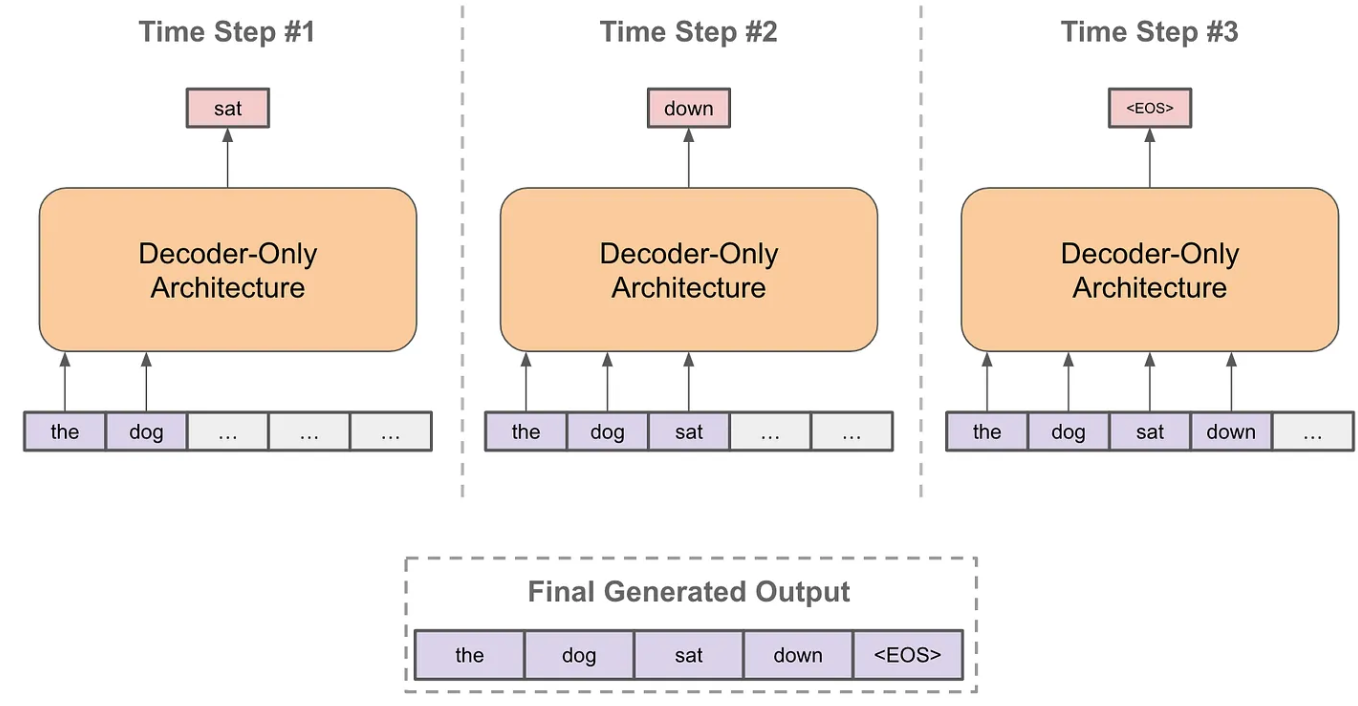
2.这里有个值得额外思考的地方是, 对于某些特定下游任务, 比如我们只做句子分类, 这种任务没有必要进行 mask attention, 使用双向的 self-attention 对于学习来说其实是有益的
Reference
转载请注明来源 goldandrabbit.github.io