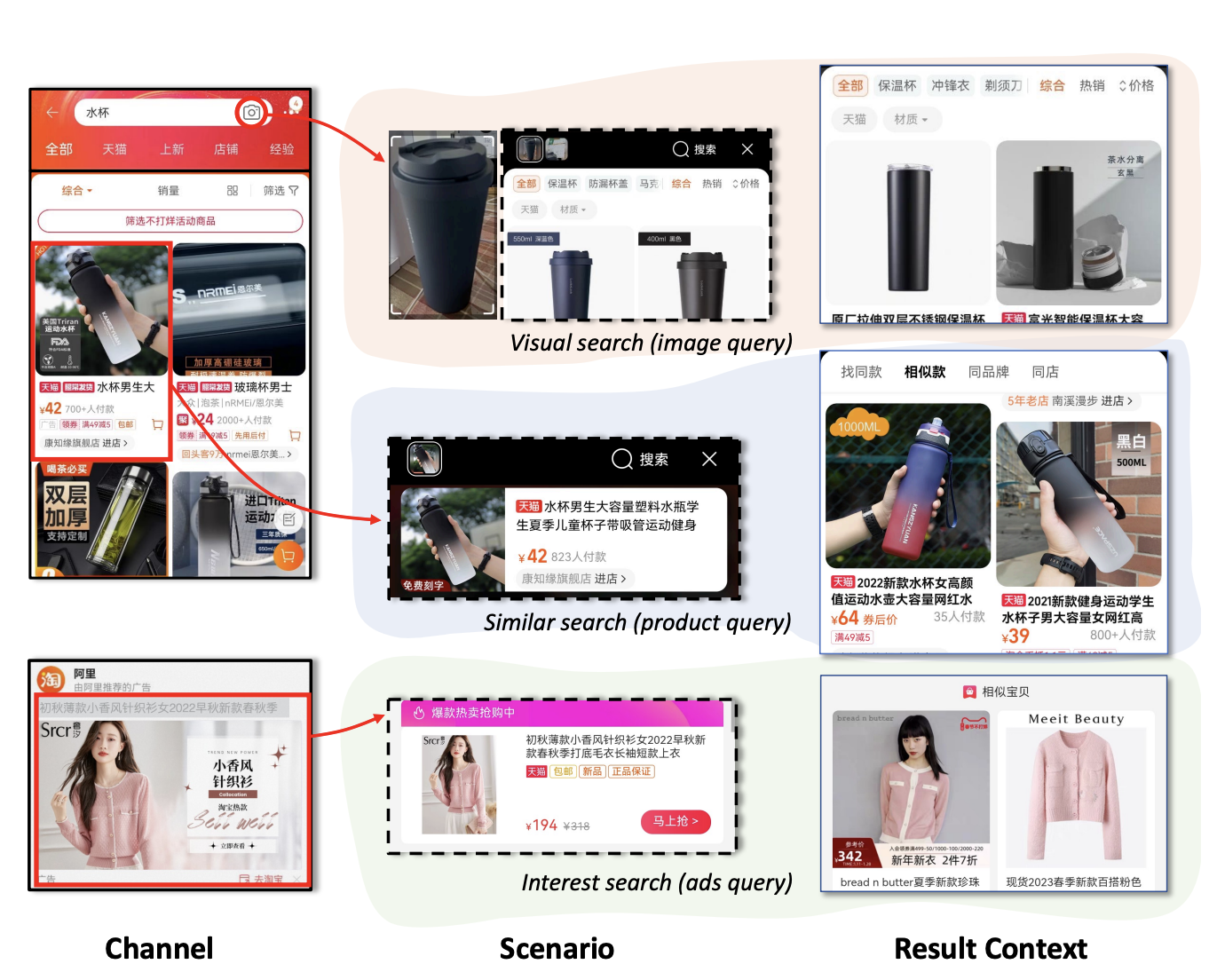
Motivation
1.梳理四种多场景建模的范式: 辅助任务范式, 分塔建模范式, 专家网络范式以及本文提出的 MARIA 范式, 并且认为传统的多场景模型的设计 (前三种范式) 均忽略了在特征这个层面上的自适应, 限制模型效果的上限
2.针对多场景自适应模型, 提出一种在特征层面做自适应场景建模的模型结构 MARIA, 将场景自适应建模下沉到特征层面, 能够针对不同的场景刻画不同特征的影响
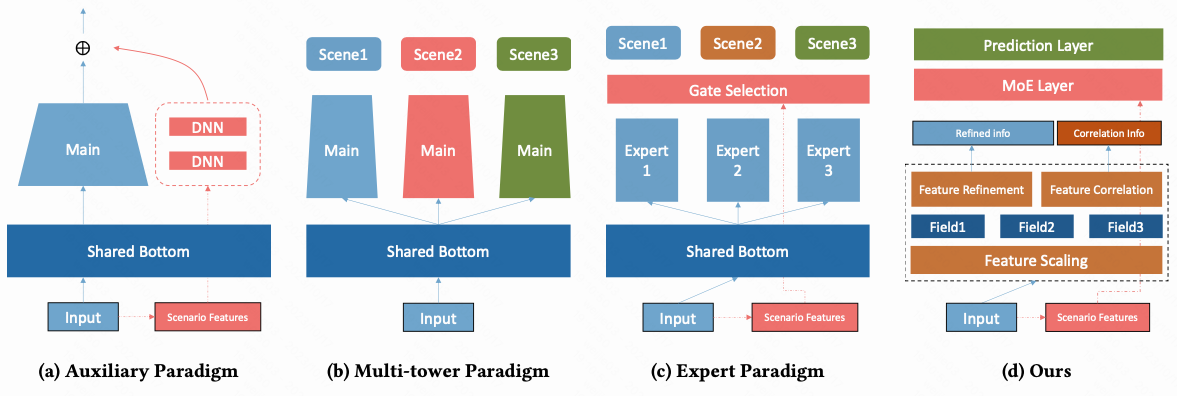
Four Paradigm of Multi-Scenario Ranking 多场景排序模型的4种范式
intuitively,
1.辅助任务范式: 将场景特征单独拆出来建辅助任务塔, 然后将辅助塔的结果和主塔做融合, 学习目标是是残差
2.分塔建模范式: shared_bottom + 分塔结构, 把所有的共享信息都集中在底座上, 场景信息建模汇聚在不同的塔上
3.专家网络范式: shared_bootom 保持不变, 将分塔结构替换成了 针对型设计的 gate 模块去做领域自适应
4.Maria范式: 在特征层面设计更复杂的场景自适应结构, 将场景自适应建模下沉到特征层面, 并通过逐级地模块增强场景自适应
Formulation
1.$h_b$ 表示行为序列 (已通过 Transformer 完成序列特征的提取) 特征
2.$u$ 表示用户相关的特征, $e_u$ 是其中的 user embedding, 另外还有 $L$ 个用户特征 field
3.$t$ 表示 trigger 相关的特征, 当且仅当有 trigger 的场景才有这个特征, 另外还有 $O$ 个特征
4.$c$ 表示上下文特征, 上下文总共有 $N_c$ 个特征
5.$x$ 表示 target 商品/广告, 其中 $e_x$ 表示商品的 embedding, 另外还有 $P$ 个商品特征
6.$e_s$ 表示场景的 embedding
7.$N_s$ 总共有 $N_s$ 个场景
Method
1.MARIA 模型分为 3 个部分, 从下往上 a / b / c 这三个部分各自有一定程度上的场景刻画建模操作, 堆叠起来构造成一个完整的结构; 在 a => b => c 这三个部分
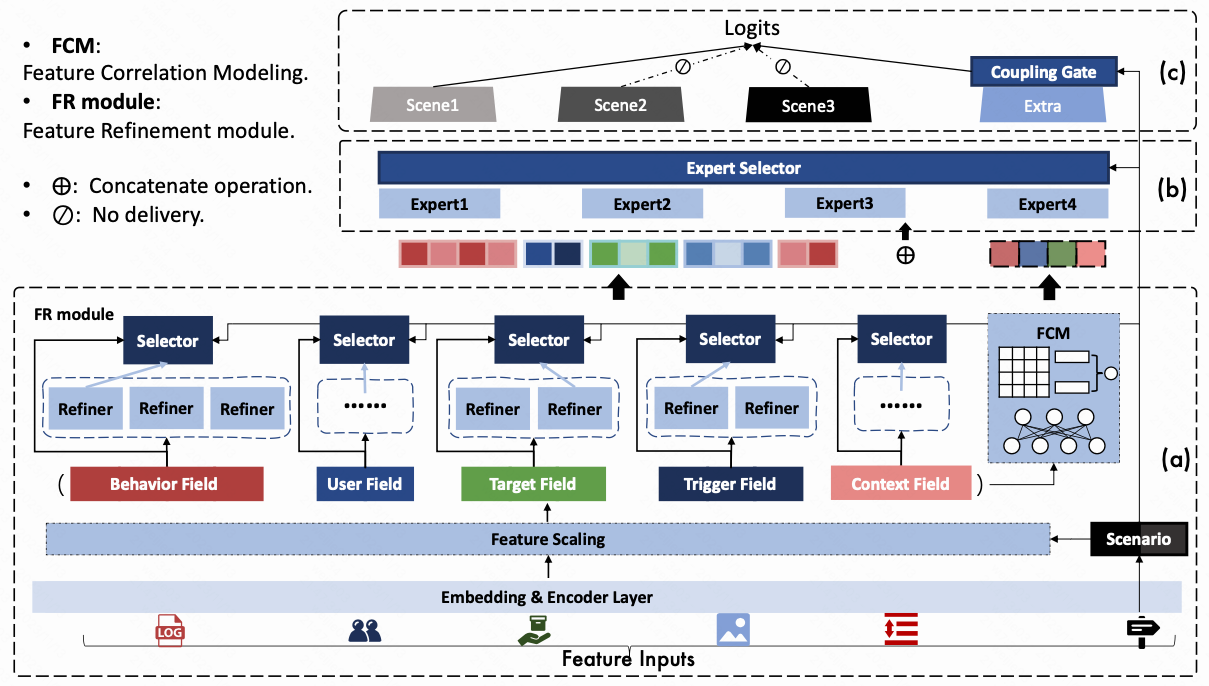
Embedding & Encoder Layer
1.商品id/用户id/trigger/context 和它们对应的的基础属性 concate 得到商品/用户/trigger/context embedding, 以商品和用户为例
2.行为序列过 Transformer 得到一个表征 $h_b$
3.各种 embedding 和行为序列表征 concat, 得到基础特征输入 $Q$ , 为了表述容易理解, 把下面的 concat 起来的每个特征组, 称为 [特征分组] , 总共有 5 [特征分组]
Feature Scaling 特征缩放
特征缩放是想在 [原子特征] 上做缩放操作, 这里的 [原子特征] 定义为某个具体 sparse_id / dense 特征, 用 $N_Q=L+P+O+N_c+4$ 来表示基础特征 $Q$ 有 $N_Q$ 个[原子特征], 然后用一个向量 $\alpha \in \mathbb R^{N_Q}$, 来对这 $N_Q$ 个分组生成对应的标量缩放系数 $\alpha_i$
这个 $\alpha \in \mathbb R^{N_Q}$ 怎么学出来的呢? 用一层神经网络 sigmoid 激活后的值 乘以外加的一个 $\lambda$ 系数
intuitively,
1.我们看下这个式子, $freeze()$ 函数表示 stop_gradient op, 把原始 $Q$ 固定住参数不参与梯度更新, 不更新的原因是避免过拟合和梯度冲突, 并且和 user embedding 和 item embedding 加上场景 embedding 拼起来做出来一个 attention weight
2.这里有个疑问是 $Q$ 里面是包括原来的 $e_u$ 和 $e_x$ embedding 的, 所以如果按照公式里面这么写, 岂不是 $Q$ 的局部还是会修改? 文章没有没明确解释这个操作如何处理
3.我们将输出的结果, 一个和 $Q$ 完全相同的表征取出来记录为 $Q_S$ , 这个新表征吸收了在不同特征分组下的 $\alpha$ 参数, 可以理解为完成了一个非常基础的特征分组的场景自适应, 记录一个新的表示为
Feature Refinement 特征精细化
1.特征精细化希望进一步提取每个 [特征分组] 的语义信息, 具体来讲, 对每个 [特征分组] 搞若干个属于这个分组的 feature refiner, 这个 refiner 是一个1层神经网络
2.这里抽象的层次相比之前的 Feature Scaling 的语义维度高了一层, 我们总共有5个特征分组, 我们就对这5个分组生成对应的 refiner, 每个 refiner 对应有对应的维度
3.比如对于 [用户行为序列这个分组] 我们搞 3个 refiner, 相当于把行为序列的特征长度 concat 到原来的 3 倍
下面 formulation 写的是 $\beta$ 的生成过程, 并且以 $\hat h_b$ 为代表说明了怎么加权
4.到这为止, 我们生成 (输出) 的表达为
5.什么是 Gumbel softmax?
Gumbel softmax 允许模型中有从离散的分布(比如类别分布categorical distribution)中采样的这个过程变得可微,从而允许反向传播时可以用梯度更新模型参数
Feature Correlation Modeling 特征相关性建模
1.我们对现在的 5 个[特征分组], 还想学一个 [特征分组之间] 相关关系, 核心原理是对每两两分组 pair 学一个内积表示 [特征分组] 和 [特征分组] 之间的关系; 为了想用内积, 要把每个分组的表达搞到一个相同的维度 $d_r$ 才能去计算向量内积
2.因此第1步我们先对每个分组过一层网络拿到相同维度的表达, 分别是 $\hat h_b,\hat u,\hat x_i,\hat t,\hat c$ 它们的维度都是 $d_r$, 然后生成一个两两内积层
3.内积层只是为了捕获特征相关性信息, 我们还是要带上原来的特征
4.到此为止, 我们已经把特征层面的事情已经都做完了, 实现了逐层增加的特征对场景的自适应效果, 并且也建模了特征之间复杂的跨域关系
MMoE Layer 多专家混合网络层
1.MMoE 这一层想在网络层面对场景进行一次自适应, 总共设置了 $N_e$ 个 experts, 对于然后构造了一个 MMoE 中间层, 其中每个 expert 是独立的全连接层网络
2.为什么说是对场景自适应, gate 网络的 softmax 的输入来自于 $W_ge_s$
Prediction and Model Optimization 分塔融合预测和损失函数
最终的多任务输出, 采用了一个分塔融合的策略: 用场景单独隐藏层 + $\alpha$ 倍的场景共享层去做融合, 融合的结果最终过一层全连接层输出最终的结果 $\hat y_{ui}$
融合系数 $\alpha_ s$ 是如何产出的? 充分利用场景的 embedding $e_s$ 计算场景的相似性分数, 具体来说, 针对每个场景的 embedding 和其他所有的场景的 embedding 做内积再求和然后归一化
intuitively,
1.采用这种分塔融合的方式, 类似于直接预估模型 ensemble 融合的方式, 这里的系数 $\alpha_s$ 起到较强的融合作用; 我理解这个融合参数的给出不一定需要一个端到端学习的过程, 因为会给模型学习带来更多的复杂度, 如果采用离线计算的结果直接作用, 可能会降低模型复杂度
From My Perspective
1.该模型从特征层面在多场景自适应上的探索更优的效果值得尝试
2.该模型采用了较多模块去耦合, 端到端建模的难度非常大, 直觉上耦合的系数过多; 在利用的时候考虑可以组件成独立的模块, 然后再在模型上去做逐层 (a/b/c) 的实验
Reference
[1]. Multi-Scenario Ranking with Adaptive Feature Learning.
[2]. SIGIR’23 | 基于特征自适应的多场景预估建模. https://zhuanlan.zhihu.com/p/641895931.
转载请注明来源 goldandrabbit.github.io