Overview
1.多阶段一致性训练方案, 级联排序模型优化, 缓解全投放链路的 sample selection bias (SSB) 问题
Formulation
1.总共有多个排序阶段的模型, 其中第 $i$ 个排序阶段为 $Ri$, 比如有 3 个阶段 Recall -> Pre-Ranking -> Ranking, 分别对应的是 $R{i-1}$, $R{i}$ , $R{i+1}$ , 每个阶段的样本的分布为 $\text{Pr}_i(X,Y)$
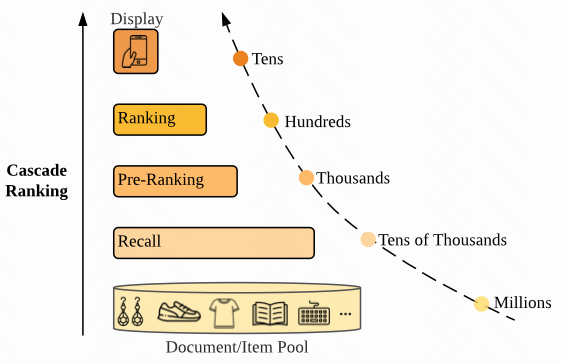
2.这个文章有一个基础设定: 优化的分布一致性最终目标是对齐到 impression/display (是否曝光) 这个维度, 即用 impression (log) 作为一致性 ground truth, 类似业务中的下发率预估模型 ; 通常每个Rank阶段都有自己的优化目标, 在这种设定下导致每个阶段的优化目标和最终进入曝光这个目标的分布是存在差异的; 作者提出一种多阶段联合训练的方法去建模各个 Ranking 阶段具备”统一对齐性质地”进入到曝光的分布一致性
Method
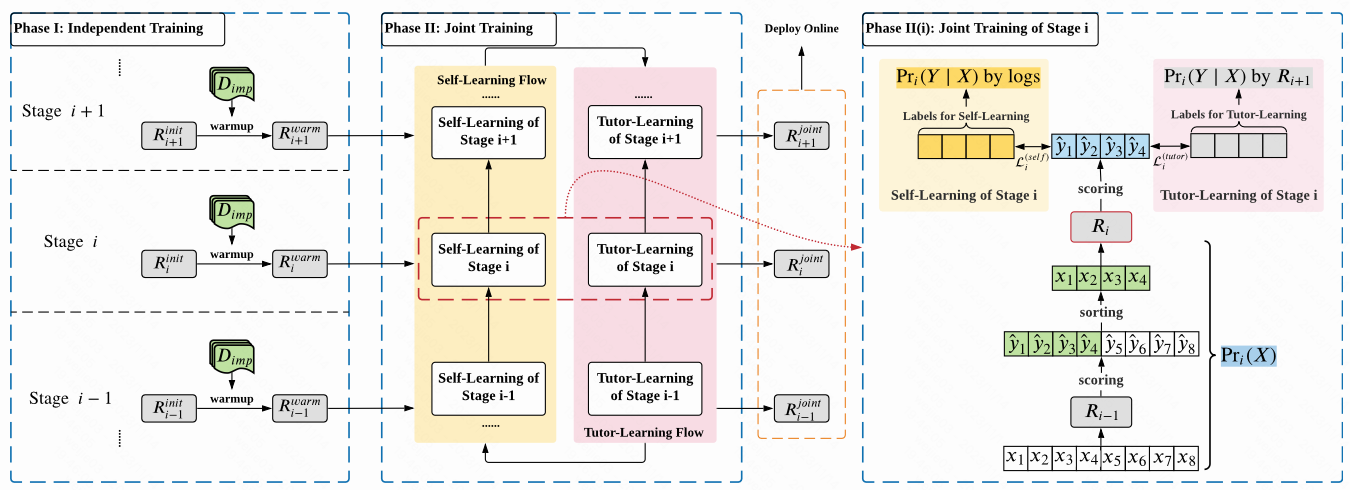
The major paradigm of RankFlow is fitting each ranker towards its own stage-specific data distribution, with the help of other stages.
the training data of each stage is generated by its preceding stages while the guidance signals come from not only the logs but also the succeeding ranker.
intuitively,
1.整个排序系统分为多个阶段 (召回=>粗排=>精排=>曝光/展示), RankFlow 的核心思想是对具体某个阶段来说, 一方面建模该阶段进入到曝光的数据分布, 另一方面要借助后续排序阶段的数据分布去进行分布统一性建模, 且两个建模过程采取同时优化的范式, 最终的收益是是能使得对全链路上下游各个阶段保持较好的分布一致性
2.具体来说, 每个阶段的训练样本都来自于前面的阶段, 训练的监督信号不仅仅用这个阶段的最终曝光 label 做优化, 还要加上后面那个阶段的 label 信息
Data Generation 数据生成
1.每个阶段用上一个阶段你的结果截断出来的 TopK 个结果做样本, 其实就是如果是精排用的样本是进入精排的样本=就是全量粗排的 TopK 截断; 如果是粗排就是用的进入粗排的样本 (这里默认进入粗排的样本和全量召回的样本不是一个概念, 用的是召回的样本做了 TopK 截断的样本, 其实就是默认召回阶段也有一个统一的相关性分)
2.因为每个阶段用了上一个阶段的样本截断生成, 所以第一个阶段比如召回阶段是没办法生成样本的, 因为它不存在上一个阶段搞相关性截断, 所以只能用随机采样的方式做生成
Self-Learning Flow 自学习流
1.每个阶段的训练 label 的生成, 其实采用的是以终为始的思想, 我们最终的目标是预测一个 $\langle q,d \rangle$ 最后会不会进入曝光, 所以如果最终进入曝光, 那么设置为正样本; 如果最终没有曝光, 那么是负样本
2.构造 loss 的时候用的是一个交叉熵损失的形式, 正负 label 已经有了, 预估分采用的是属于该阶段的相关性分数, 也就是基于模型 $R_i$ 预估出来的分
Tutor-Learning Flow 监督下的学习流
1.除了 self-learning 的生成之外
Reference
[1]. RankFlow: Joint Optimization of Multi-Stage Cascade Ranking Systems as Flows.
转载请注明来源 goldandrabbit.github.io