Motivation
1.提出一种 Scenario-Adaptive 场景自适应的 CTR 预估网络 SATrans, 创新点是设计了显式的场景特征 encoder 模块, 并基于 Transformer 结构设计了如何将场景特征和场景无关特征之间的特征交叉
Formulation
数据集
特征表示为
分为场景 [相关的特征] 和 [场景无关特征]
Multi-Scenario Modeling 多场景建模
整体结构分成两个部分
1.Scenario Encoder 场景编码器, 本质是将场景特征做一个基础的编码, 提供给后续特征交叉使用
2.Scenario-Adaptive Interaction (SAI) Layer 场景自适应交互层
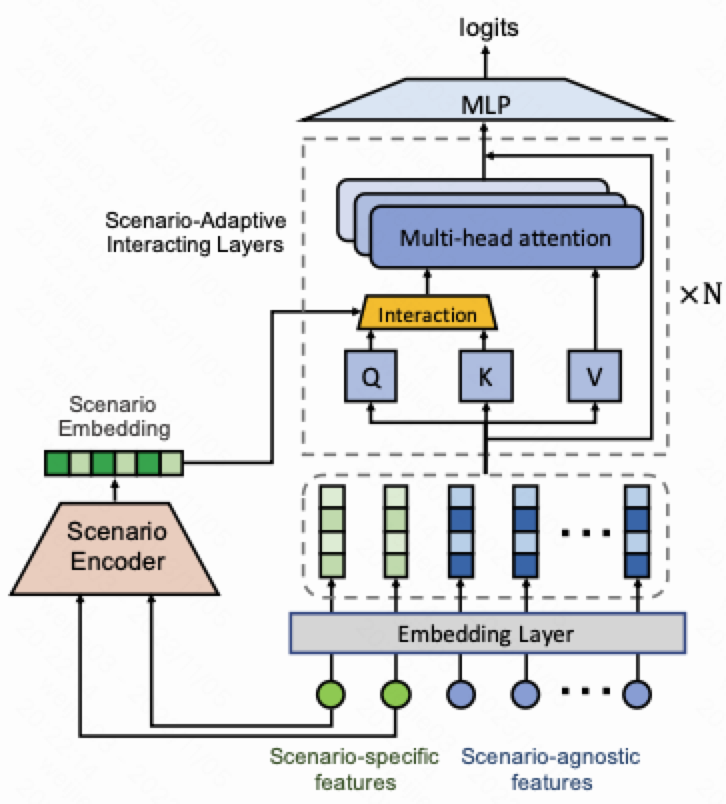
该模型工作原理如下:
1.场景编码器将 [场景相关特征] ${\bf x}^s$ 作为输入获得一个固定长度的场景 embedding $\bf s$, 另外将所有特征 $\bf x$ 过 embedding 层 获得 ${\bf e}=[{\bf e_1};\ldots;{\bf e_N}]$
2.堆叠 $l$ 个场景特征交叉层, 每个交叉层将场景相关特征和原始特征 (或者后面的隐层) 做场景特征自适应交叉, 得到 $l+1$ 层, 最终达到一个场景自适应交叉的效果
Scenario Feature Encoder 场景特征编码器
关于场景特征编码器作者比较了3种设计, 依次是 independent embedding => encoding network => embedding network with Structural Position IDs
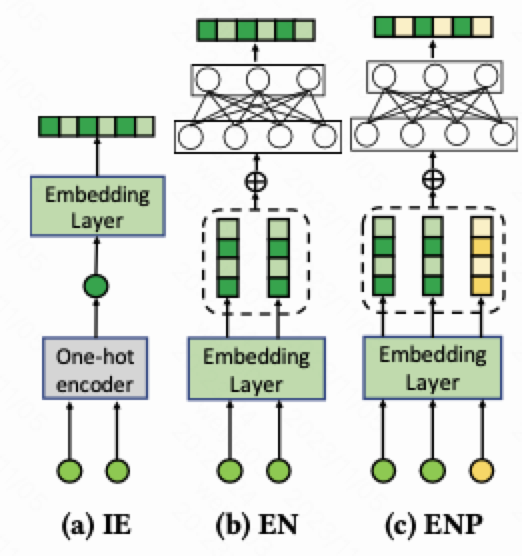
1.独立的场景 embedding 存在不能进行场景共享的问题, 不建议采用; 生成 embedding是 ${\bf s}$
2.encoding 网络这种方法增加了一个变换, 得到的固定长度的编码
3.在 encoding 网络的基础上增加了2个相应的结构信息, 生成的是一对 embedding $\bf s_Q$ 和 $\bf s_k$
$l$ 这个结构信息标识的是在之后的场景自适应交互层的第几层
$h$ 这个结构信息标识的是 $h\in {Q, K}$ position 信息 ${\bf p}_{l,h}$ 是要和后面的交互层的 $Q$ 还是 $P$ 去做运算
Scenario-Adaptive Interacting Layer 场景自适应交互层
1.首先抛开场景这个因素, 如果单纯设计特征交叉可以使用 multi-head self-attention的机制
2.然后将这种自动特征交叉的机制, 可以扩展到兼容场景特征和全部特征这两类特征上, 从结构由简单到复杂, 依次设计了以下三种结构:
mha 如何做特征交叉 ? 对于 第 $i$ 个特征 $h_i$ (第1层情况下 $h_i=e_i$) 和 $h_j$ 个特征做 transformer 的 $K, Q, V$ 的 self-attention 操作
如何将 mha 这种扩展到 $h_i,h_j,{\bf s_Q}^{(h)},{\bf s_K}^{(h)}$ 这种四元素的 attention score ? 单独设计一个网络产生 weight
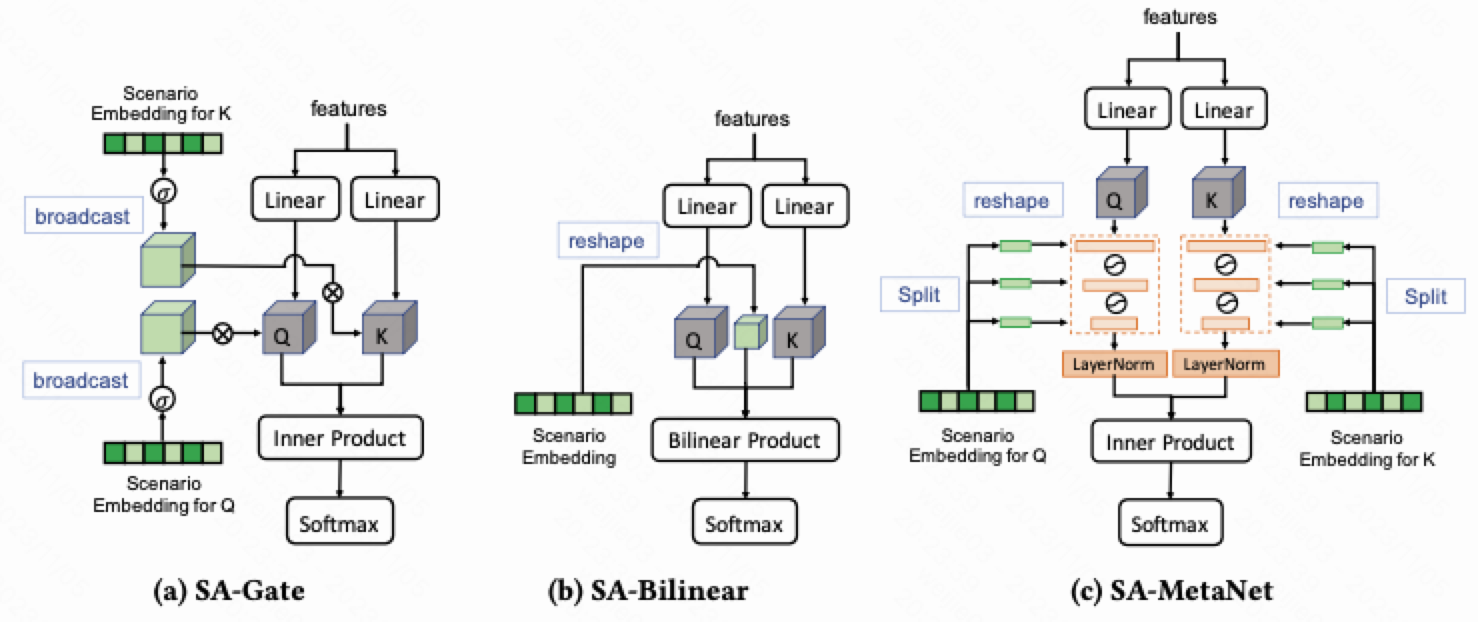
为了设计这个交互结构, 从简单到复杂, 用了3种方法
(i). SA-Gate (Bit-wise)
(ii). SA-Bilinear (Bilinear)
(iii). SA-MetaNet (Nonlinear)
对于第 1 种: SA-Gate (Bit-wise) , 引入 gate 去做激活, 然后用 inner product 做 attention score
对于第 2 种: SA-Bilinear (Bilinear), 先引入的是 1 个场景感知矩阵 ${\bf S}$ , 这个矩阵的维度是由原始的场景 embedding 强行 reshape 过来的, 然后再结合用双线性公式算 attention score
对于第 3 种: SA-MetaNet (Nonlinear) 需要看下细节
Reference
[1]. Scenario-Adaptive Feature Interaction for Click-Through Rate Prediction.
转载请注明来源 goldandrabbit.github.io