Motivation
- 说明预估任务中数据增强起到关键的作用
- 提出 SimLR: 一种自监督的对比学习框架: 其中提出一种非线性变换方法针对原始的表达先进行变换, 进而学习原有表达的多种变换表达的对比损失, 可以有效地提升表示学习的质量
- 相对于有监督学习, 对比学习需要调大 batch-size, 并且训练更多的 step
Method
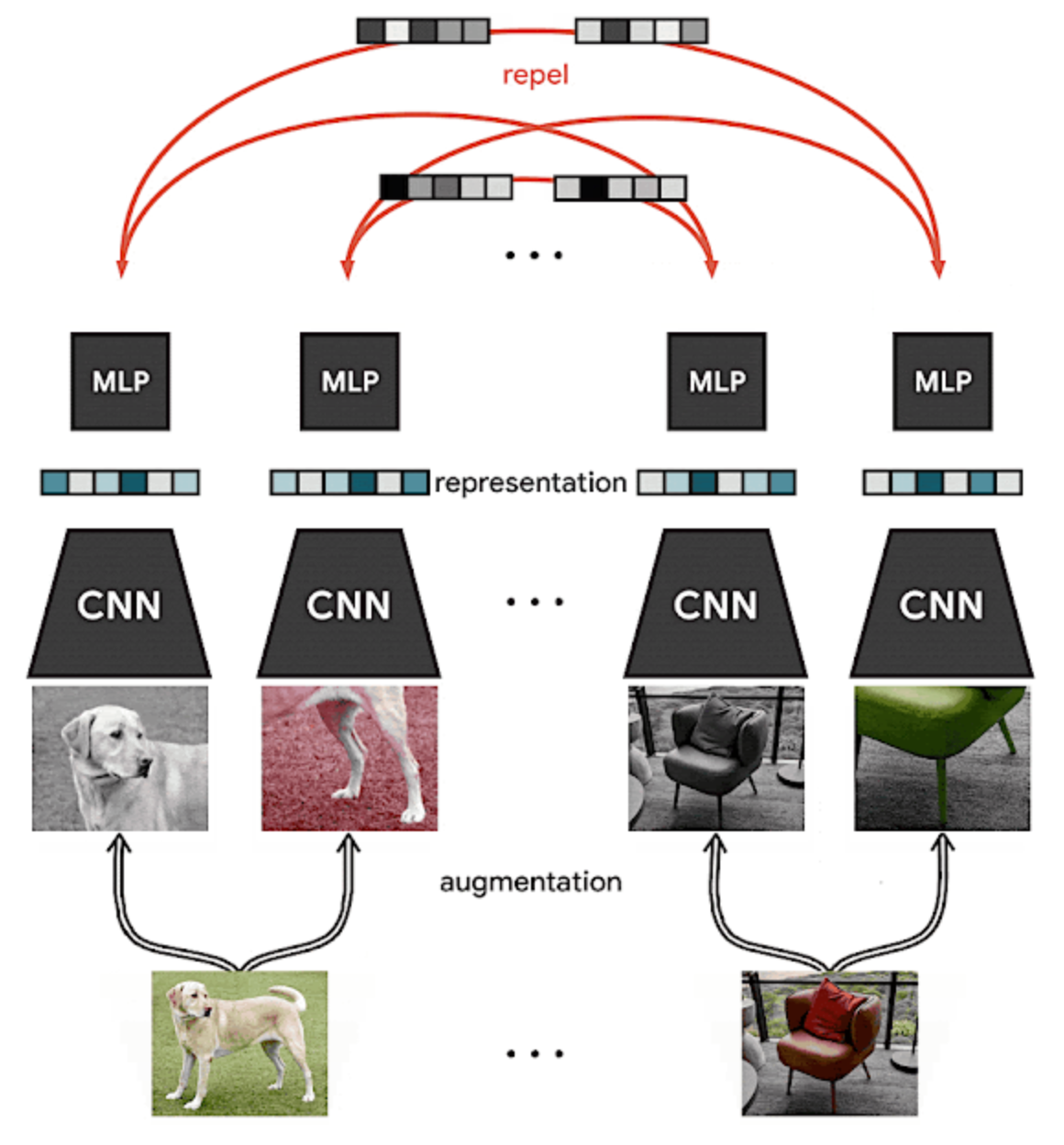
提出了对比学习的框架, 该框架分为四个模块
- Data Augmentation. 数据增强模块: 对于单个样本随机 $x$ 产生两个相关的 view $\tilde x_i$ 和 $\tilde x_j$ , 这两个增强的样本都被视为正样本; 在这篇文章中针对图像采用了三种方法 random cropping/random gaussian blur/random color distortions, 在实验部分通过对这三类方法进行组合达到了非常好的效果
- base encoder $f(\cdot)$. 基础编码器用于提取增强样本的表达向量, 是一个任意的网络, 作者针对图像任务采用了 ResNet
- project head $g(\cdot)$. 投射头是一个比较小型的网络, 作者采用的是一层神经网络
- constrastive loss function . 对比学习损失函数. 给定正样本对的集合 ${\tilde xk}$ , 其中某个正样本为 $\tilde x_i$ 和 $\tilde x_j$ , 构建一个对比预估任务, 目标是对于 $\tilde x_i$ 来说识别 $\hat x_j \ \text{in} \ {\tilde x_k}{k\neq i}$ .
对一个 minibatch 来说总共有 $N$ 个样本, 总共产生 $2N$ 个增强样本; 对于某 1 个样本而言, 定义 1 对正样本, 其余 $2(N-1)$ 个增强样本被看做负样本;
定义两个样本之间的相似度为 $sim(u,v)$ 比如采用余弦相似度
对于一个正样本对 $(i,j)$ 而言
给出 SimCLR 算法伪代码

Training Detail 训练细节
- 采用大的 batch size 训练: from 256 到 8192
- 采用标准的 SGD 或者 Momentum 训练会不稳定, 采用 linear learning rate scaling 的方法, 并且采用 LARS 优化器
- 对不同的 device 采用一个 global 的 BN
Reference
[1]. https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html
[2]. A Simple Framework for Contrastive Learning of Visual Representations.
转载请注明来源 goldandrabbit.github.io