Motivation
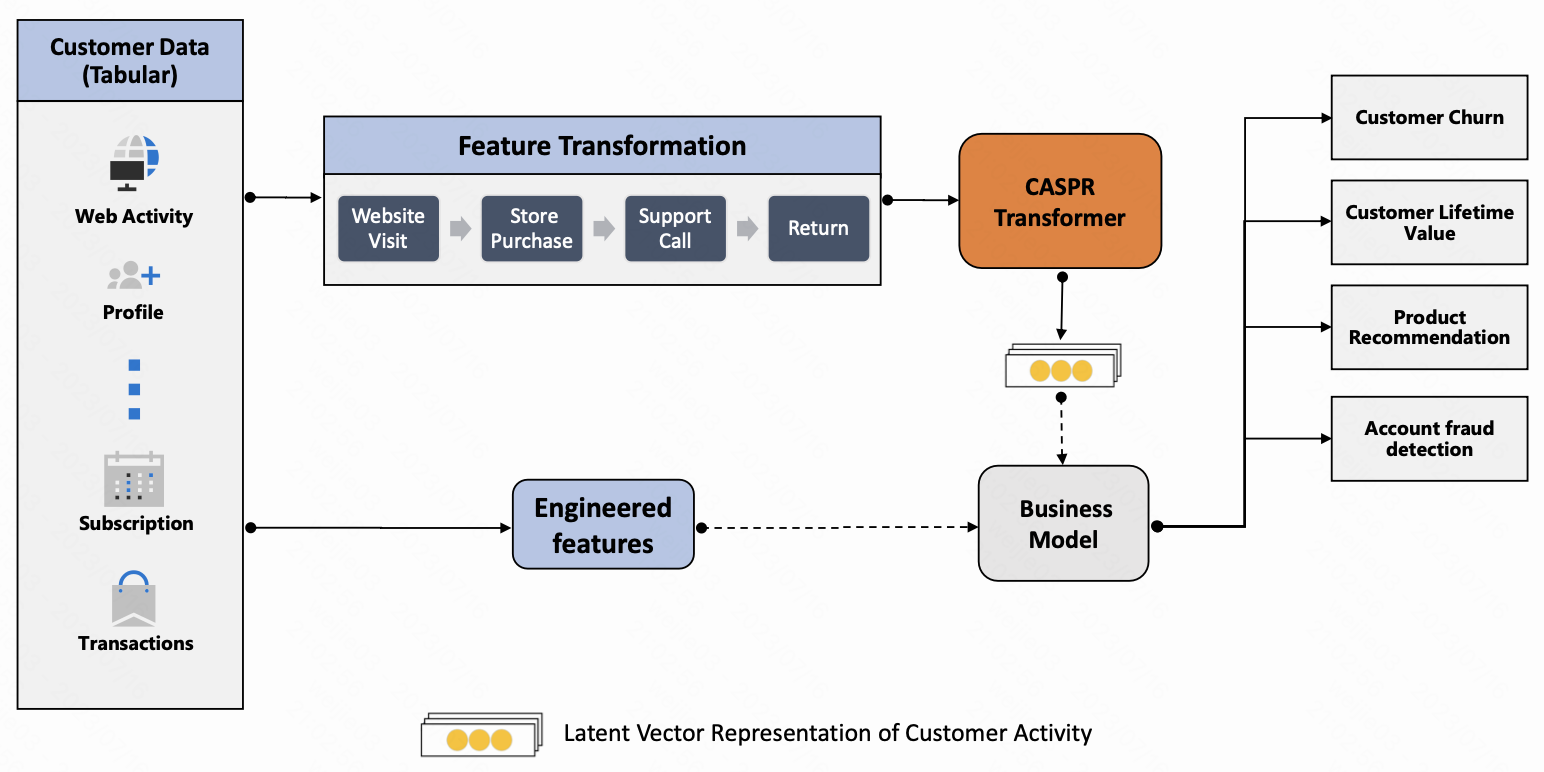
1.提出一个基于 customer 活动序列的表示学习的方法 CASPR, 用于下游的 LTV 预估/用户流失预估/商品推荐/反作弊
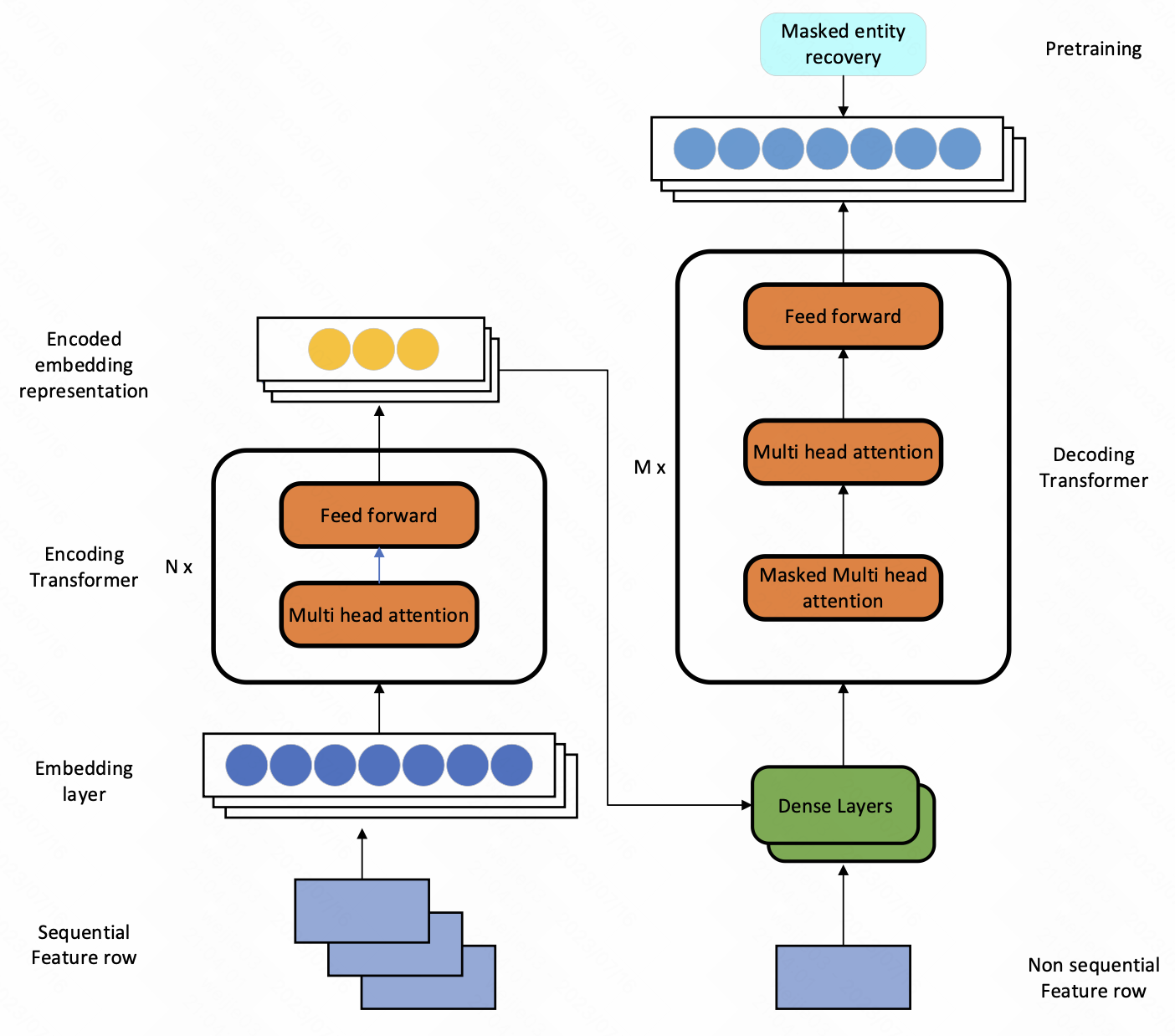
CASPR 网络结构
intuitively,
1.CASPR (Customer Activity Sequence-based Prediction and Representation) 的目标是学习一个向量表达 $v_E$ , 这个表达把 entity 所有有序的活动信息 (和其他属性) 全部进行了编码; 看到这个上图结构, 除了没有 position embedding 之外, 这和 machine transilation 的 encoder-decoder block 有啥区别 ?
2.对于每个 entity, 生成一个子数据集 $D_E$, 其中 $A$ 代表活动, 不同 entity 之间的时间戳无需对齐
每个 entity, 给到 transformer 结构的输入是 entity 的原始活动向量
然后经过 Transformer encoder block 结构得到一个 encoded embedding representation; 然后将encoded representation 和非序列特征向量 (比如年龄/身份/任期) $A_{E, non-sequential}$ concat 起来, 通过几层 dense layer, 得到最终的 encoded output
3.如何训练出来 entity 的 embedding? 采用的是 masked entity recover task
We then optimize the reconstruction loss by comparing the original sequence of vectors with the output of the decoder. We use the mean square error loss for numerical attributes and cross-entropy loss for the categorical attributes to measure reconstruction loss.
intuitively,
1.训练方式就是照搬 bert 的训练方式, decoder 的 output 来自于 input 序列随机 mask 掉 30% 的活动
2.在计算 loss 的时候需要分开计算, 计算 loss 的时候 numerical 这部分算 mse 的 loss, categorial 这部分算 cross-entropy 的 loss
3.这种不加处理的训练用户行为 representation 的方式不太符合直觉, 用户的行为活动之间的相关性显然低于语言模型 token 之间的相关性
Reference
[1]. CASPR: Customer Activity Sequence-based Prediction and Representation. Pin-Jung Chen et al.
转载请注明来源 goldandrabbit.github.io