Motivation
1.Customer Life Time Value (LTV) 预测任务在诸多业务场景中带来收益, Kuaishou 业务场景中最典型的例子快手的用户增长场景; 另外一个典型的例子是在广告投放产品中, 基于 ROI/ROAS 出价产品依赖预估用户 (长期) 付费金额/成交 GMV
2.建模 LTV 的一般方式采用训练 regression model 的方式进行建模, 并采用 MAE/MSE 的方式去评估; 相比于 CTR/CVR 建模任务, LTV 预估难度通常更大, 难度高的核心原因包括两点:
(i). 没有考虑业务场景中 LTV 的分布特点. 通常对 LTV 问题采用 MAE/MSE 回归指标计算 loss, 但是这回归指标对异常点都比较敏感, 因此基于 SGD 的训练过程收敛性和稳定性都很难保证
(ii). 忽略了不同时间跨度周期的 LTV 建模之间的存在的确定性关系. 比如我们需要分别建模 30天/90天/180天/ 365 天的 LTV, 分别表示为
显然, 更长的时间周期的 LTV 应该比更短时间周期的LTV的值预估要高, 从建模原则来看, LTV建模需要满足时间跨度有序性下的 LTV 保序性的性质, 也就是满足
但在之前的回归任务或者 multi-task learing 中, 并没有满足 LTV 保序性质; 同时建模的难度来上说, 越长时间跨度的 ltv 建模 task 的难度理论上更大
Formulation
给定固定的特征向量 $\rm x$, 我们需要预估的是 next N 天的 ltv, 记录为 $LTV_N$ , 其中 $N_t$ 表示第 $1,2,…,T$ 个 LTV 任务
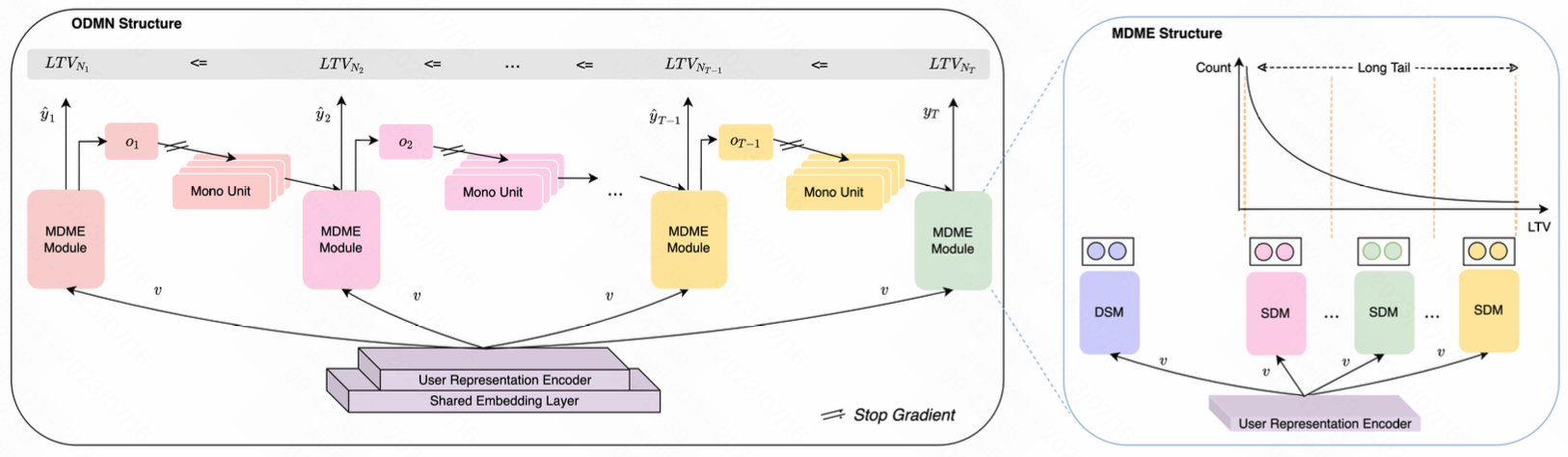
Order Dependency Monotonic Network (ODMN, 保序单调网络)
1.ODMN 结构主要解决LTV预估保序性的问题
exhaustively,
1.对每个 time span (时间跨度) 的 $LTV_i$ 进行多任务建模, 多任务建模采用的是 shared-bottom 的结构 (MMoE或者PLE)
2.对于每个 MDME 的输出, 抽取一个 $o_t$, $o_t$ 表示 normalized bucket multinomial distribution
3.对 $o_t$ 进行一个 Stop Gradient 操作 (实现参考 tf.stop_gradient()), 得到一个 Mono Unit (单调单元), 单调单元是一层没有负数参数的 mlp, Mono Unit 的作用是捕获上游任务的多项式分布的变化趋势, 借助 Mono Unit, 下游任务可以感知上游的分布变化从而做出相应的分布调整
Multi Distribution Multi Experts (MDME)
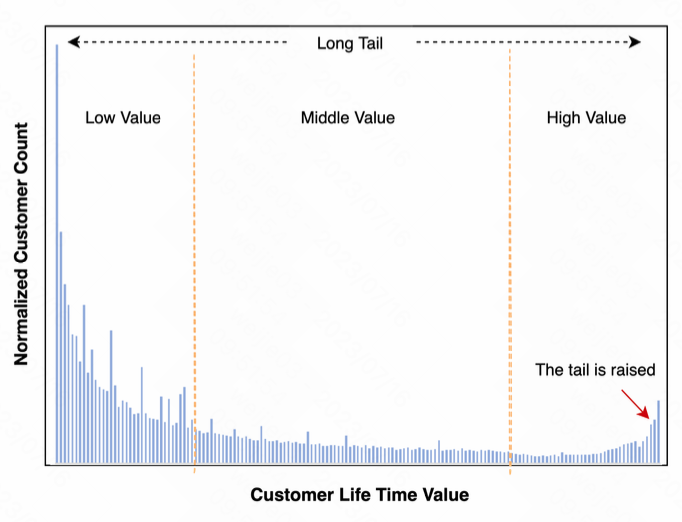
1.MDME 结构主要解决的是每个time span下的 LTV 预估中自适应 LTV 分布的问题. 关键词是”分割分布”
2.MDME 的思想是把比较复杂的 LTV 预估问题分解成若干个子问题, 如何分成若干个子问题呢? 我们通常认为相对均衡的分布是比较好预估的, 但是分布比较不均衡的分布是难以预估的; 这里我们通过整体不均衡分布的样本”切”成多个均衡的多个分段进行预估, 每个分段下的样本不平衡度会大大降低
exhaustively,
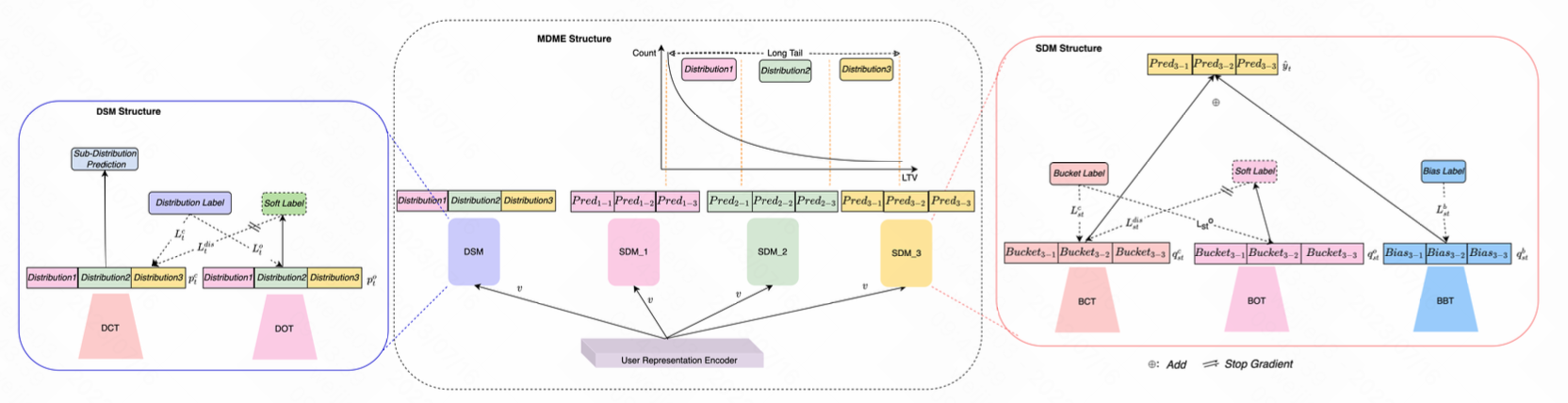
1.理解 MDME 的结构, 需要顺序依次理解 DSM=>SDM=>MDME; MDME简单来说, 先决定属于哪个子分布, 然后决定属于哪个ltv分桶
2.Distribution Segmentation Module (DSM, 分布分割模块/样本分割模块) 实现了将样本按照子分布方式进行分割; 也就是将 [样本] 映射到 [子分布上], 学习的是 [样本id] 到 [子分布id] 的映射, 实现上是一个多分类问题, label是子分布的id; 对于在样本中占比很高的情况, 比如0值, 我们把这类样本视为一个独立的子分布单独进行处理
3.Sub-Distribution modeling Module (SDM, 子分布建模模块) 实现了将 [子分布] 继续映射到 [ltv分桶] 上, 学习的是 [样本id] 到 [ltv分桶id] 之间的映射, 实现上是一个多分类的问题; 我们可以通过调整分桶的宽度, 从而使得每个分桶的样本数量接近相等; SDM 实现了每个ltv分桶内的样本不平衡度大大降了
4.基于 2 和 3 这两步分割, ltv 预估难度因为”每个ltv分桶里面的 ltv 样本分布相对更均衡”而降低
5.对于SDM结构, 单独还增加了个一个bias coefficient. 这里对 ltv 值采取用了 min-max 规范化压缩到 [0,1] 区间, 然后对bias系数采用MSE指标进行回归, 因为MSE指标对异常值非常敏感, 所以这个回归结构的引入使得 [增加一个对值 ltv range 限制] 和 [增加对loss的梯度变化的限制]
6.DSM 和 SDM 中的两个对应的多分类的结构对应的起个名字叫 DCT/SCT, (CT 代表 classification tower的意思), DCT/SCT 的结构的输出都是 softmax 的结果; 然后将 DCT 的预估概率(也就是每个子分布的概率), 记作 $o_t$, 表示第 $t$ 个LTV预测中任务的表达
7.DSM 和 SDM 中, 还新分别增引入了 Ordinal Regression (保序回归) 结构 DOT/BOT (其中OT代表ordinal tower), 基于保序回归的结构输出的是sigmoid之后的值; DOT 和 BOT 做为一个 solt label 去通过蒸馏的方式监督 DCT 和 BCT 的学习
8.上述结构的形式化表达 (个人感觉本文公式抽象功底还有待提升): 将 LTV 分成 $S_t$ 个子分布, 每个tower $s_t$ 都有两个输出
在预估 LTV 时候
Reference
[1]. Billion-user Customer Lifetime Value Prediction: An Industrial-scale Solution from Kuaishou. https://arxiv.org/abs/2208.13358. Kunpeng Li et al.
转载请注明来源 goldandrabbit.github.io