Background: 什么是 Ordinal regression?
In statistics, ordinal regression, also called ordinal classification, is a type of regression analysis used for predicting an ordinal variable, i.e. a variable whose value exists on an arbitrary scale where only the relative ordering between different values is significant.
It can be considered an intermediate problem between regression and classification. Examples of ordinal regression are ordered logit and ordered probit.
Ordinal regression turns up often in the social sciences, for example in the modeling of human levels of preference (on a scale from, say, 1–5 for “very poor” through “excellent”), as well as in information retrieval. In machine learning, ordinal regression may also be called ranking learning.
intuitively,
1.ordinal regression (有序回归) 又叫做 ordinal classification (有序分类), 本质上要做的事情是对一个有序的变量的预测; 目标上是对一个样本上做分类, 虽然名字叫做 regression, 但在做法上通常是一个分类的任务; 这个分类任务的特殊性在于, 类别之间是有确定性关系的, 更具体来说类别之间是有序的
2.ordinal regression 的典型应用有age estimation (年龄估计) , aesthetic assessment (美学评估) 还有 social sciences (社会学领域)
3.ordianl regression 问题可以看做分类问题和回归问题的中间问题; ordinal regression 通常用分类问题进行建模, 模型除了考虑分类损失之外, 还更要考虑类别之间的序关系, 使得 [与真实值的标签排序更近的误判] 的损失远小于 [与标签距离更远的类别的误判] 损失
4.为什么我们要一定做 ordinal regression 而不是直接去 regression 或者 classification 呢? 我的理解是: 当待预估的连续值是很难有清晰的物理定义或者预估精确值难度非常大时候, 只用回归或者只用分类都是建模不够全面的, 需要一种兼顾的做法
Motivation
1.作者认为 ordinal regression 任务的关键在于 adjacent categories distinction (相邻类别区分), 因此提出了在建模过程中 distinguish the adjacent categories gradually (逐渐区分相邻的类别) 这种范式
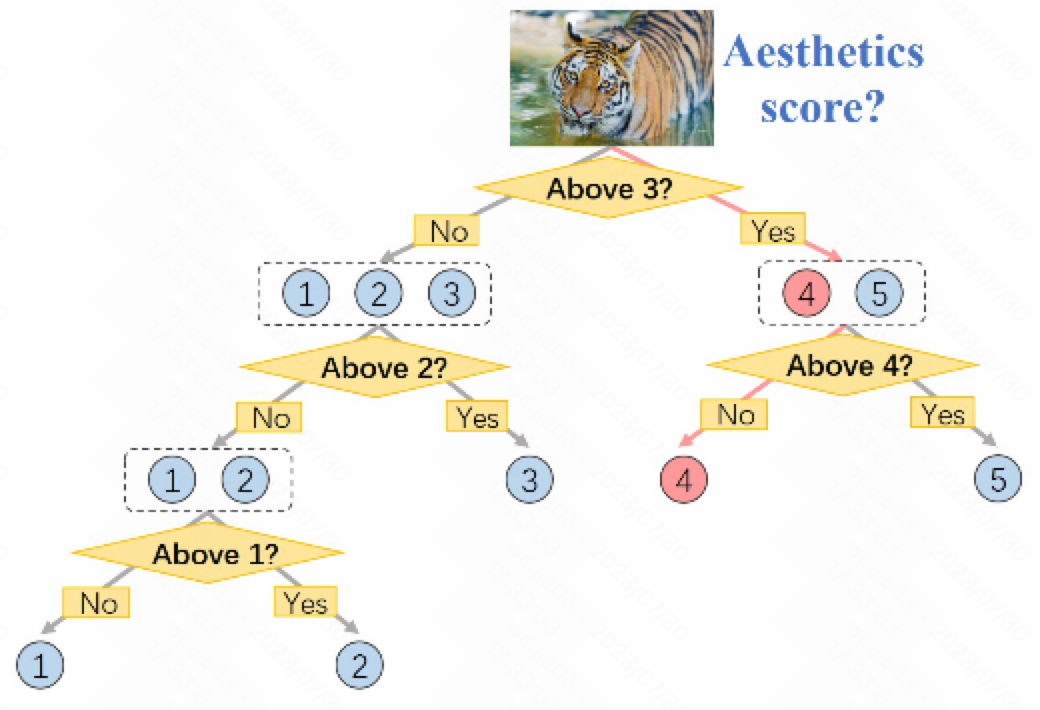
2.受到二分搜索思想 (有序数组中搜索元素, 设置个二分target, 只用target去对比左右边界) 的启发, 我们可以将 ordinal regression 分解成一系列的二分类的step, 每个step中, 我们只聚焦在处理一对相邻的边界. 举个例子: 对于aesthetic assessment (美学评估任务), 也就是输入一张图片 (比如如下图的一张老虎的图片) 目标建模并输出这张图片的美学评分 (比如1-5分); 美学评分的定义是模糊的, 很难直接回归出来一个精确的评分; 但是我们可以设置多个分类任务, 这张图片是否>1分, 是否>2分, 是否>3分, 是否>4分
3.提出一种 ordinal regression 的 sequence prediction framework (序列预估框架): Ord2Seq, 核心思想是将 ordinal regression 的问题转化成一个 sequence prediction task (序列预估任务) , 我们预测的目标从单一的 category label 转化为 binary label seq和 multi-hot label seq 的预估
Ord2Seq
Order2Seq 这个框架总共分为4个部分
1.Label Transformation and Multi-hot Label Genration (label转化和Multi-Hot label生成)
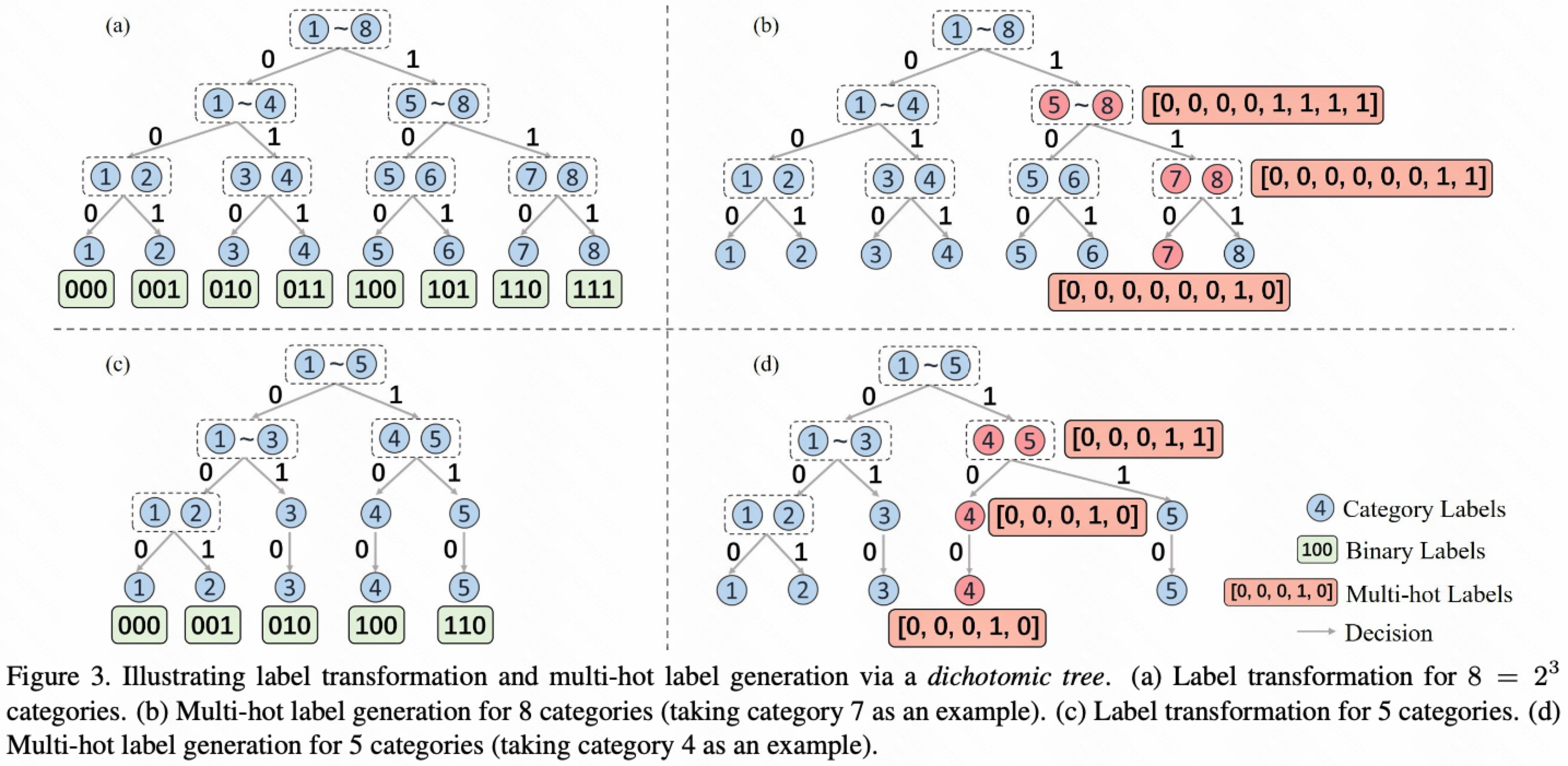
如上图所示, 共有三种 Label 编码的形式
(i). Category Label: 基础的ordinal类目Label (例如1-8总共8个整数), formulation: $C$
(ii). Binary Label: 基于二叉树生成的二进制Label, 二进制label对所有的叶子节点实现了编码, 例如分类1为000, 分类2为001, 分类3为010… formulation: $y{target}=[s,c_1,c_2,\ldots,c{d-1}]$
(iii). Multi-hot Label: 也是基于二叉树生成的Label, 但是基于Multi-hot的形式进行编码, 只有Binary Label下的叶子节点表征的二叉树的信息不够完整, 非叶子节点没有办法得到一致性的表征, 因此还需要增加一个Multi-hot的编码Label; 比如对于 [5-8] 这种非叶子节点, 可以编码为 [00001111], 对于 [7-8] 这种非叶子节点可以编码为 [00000011]; Multi-hot编码也能自动的编码叶子节点: 例如对于叶子节点7可编码为 [00000100]
With the supervision of multi-hot label sequences, the model can first predict a probability sequence and then output the binary label sequence based on the predicted probability sequence.
intuitively,
1.在这种multi-hot label sequences下, 模型可以分两步进行预测, 第一步先预测属于哪个序列, 第二步再预测属于哪个二分类
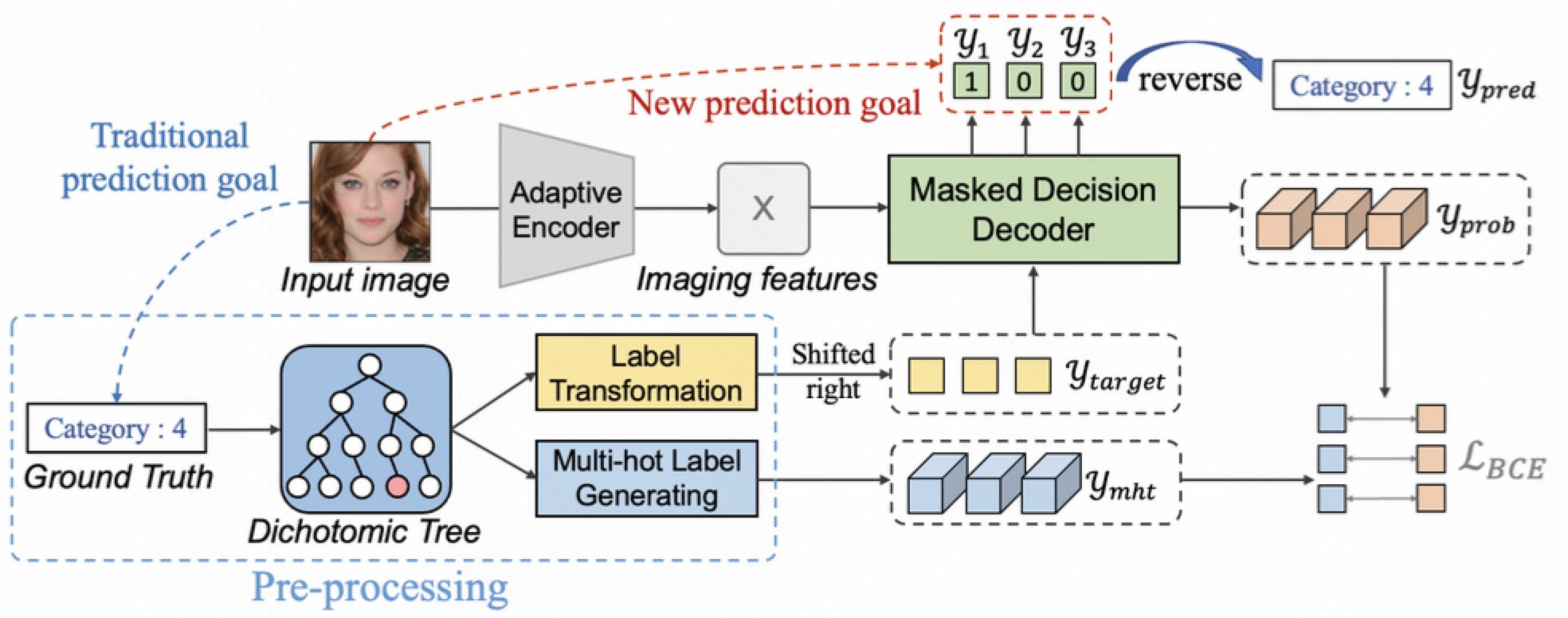
2.Adaptive Encoder (自适应编码器)
(i). 将特征 $X$ 和 $y_{target}$ 作为输入给到 Adaptive Encoder里面, 输出一个二分类序列 $y$
(ii). 这个Encoder的结构可以根据任务去进行设定, 只是一个特征抽取器, 比如图像特征就用 CNN 或者 Transformer backbones
3.Masked Decision Decoder (掩码决策解码器)
解码器包括三个部分
(i). Label Embedding 采用的是position embedding的方式
(ii). Transformer Decoder 采用的是原始的 transformer decoder 的解码结构, 直接照搬过来.
(iii). Masked Decision
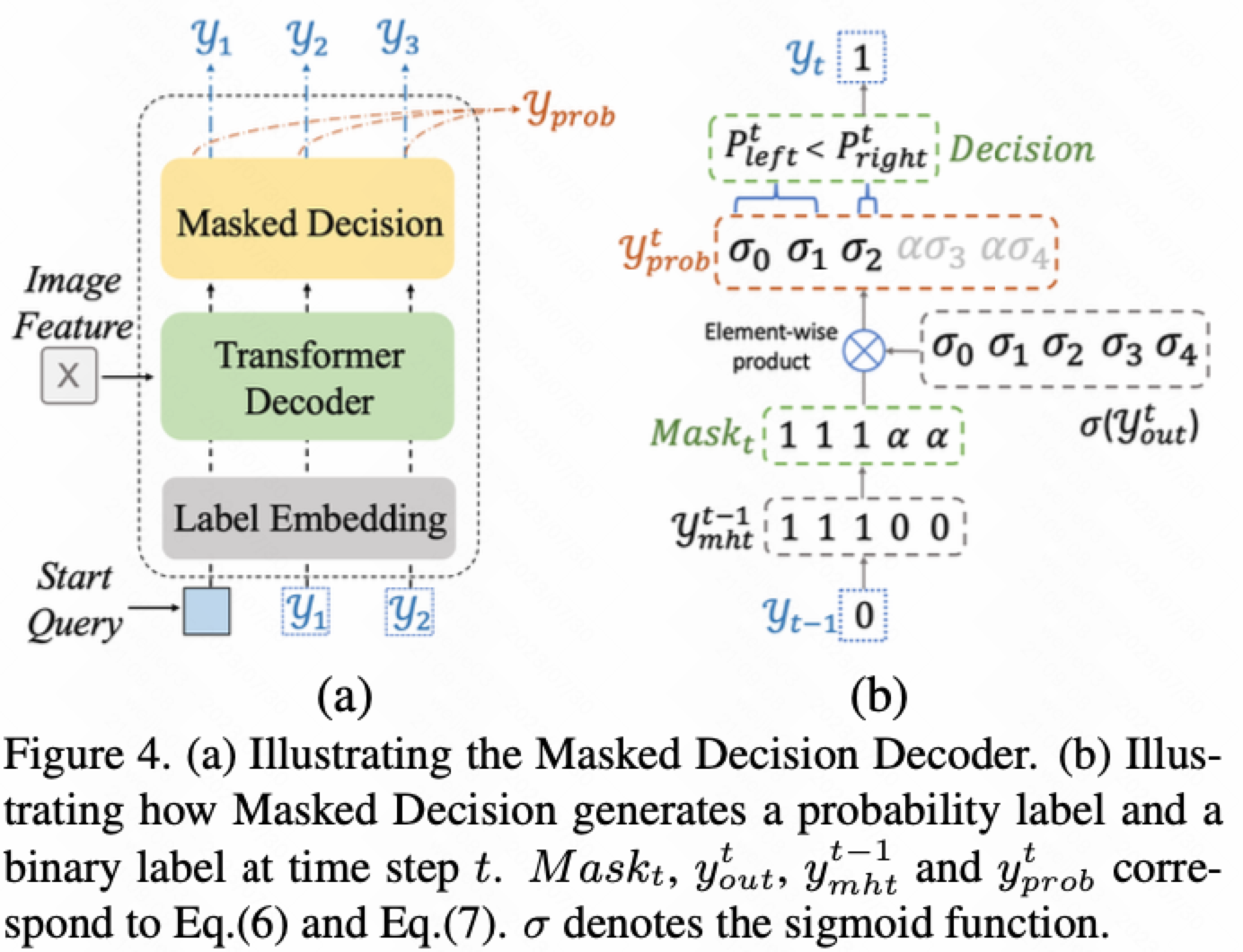
决策策略
4.Loss Function (损失函数)
Now My Perspective
1.Ordinal Regression 的优势是什么? 我的理解是引入更多个的, 有序的, 难度更低的任务处理, 去替代原本直接预估1个难度很大的任务; 使用该建模思路最典型的例子是 age estimation: 输入一张人脸图片, 我们想预估这个人的年龄, 这是非常难的, 比如一个 23 岁和她 24 岁其实未必有非常本质的区别; 我们很难精确地预测一个年龄数字, 但是我们可以尝试去预估是否>20, 是否>22, 是否>24, 是否>26…通过一系列的分类任务可以将我们待预估值逼近到较小的范围内, 然后再进行最终处理得到相对精确的预估结果
2.Ord2Seq 这种框架的优势是什么? 是一种比较具备通用性的框架
3.展望深入的优化: 继续深入思考 ordinal 的分布建模. 在初步接触 ordinal regression 问题的时候, 有想到用一种端到端的, seq2seq 的方式去建模多个 binary 问题的方式, 可以有效避免各种 multi-task 产生的问题; 当看到这篇 paper 提出的框架竟然已经被构建的非常全面和完整了 (和大佬在直觉上的想法居然惊人的一致, 观点碰撞的感觉实属奇妙), 但是这种框架应用在实际问题中还需要更多地考虑 ordinal variable 的分布情况
Reference
[1]. Ord2Seq: Regarding Ordinal Regression as Label Sequence Prediction. Jinhong Wang et al.
转载请注明来源 goldandrabbit.github.io