Motivation
1.针对 LTV 预估问题, 提出采用 Multi-view 的框架 CMLTV: 训练多个不同视角下的 regressor 然后再融合预估 (而不是单一的 regressor), 通过对多个 view 下的预测结果去集成, 更能高效地处理样本存在的 noise 和样本 imbalance 的问题
2.提出一个 hybrid contrastive learning (混合对比学习) 的方法, 来自监督地充分利用学习 (正负) 样本之间的关系, 目标缓解 ltv 数据稀疏性的问题; 所谓 hybrid, 是指同时进行 regression 对比学习和 classification 的对比学习
3.CMLTV 模型在华为游戏中心部署, 获得了 32% 的 GMV 提升增益
Method
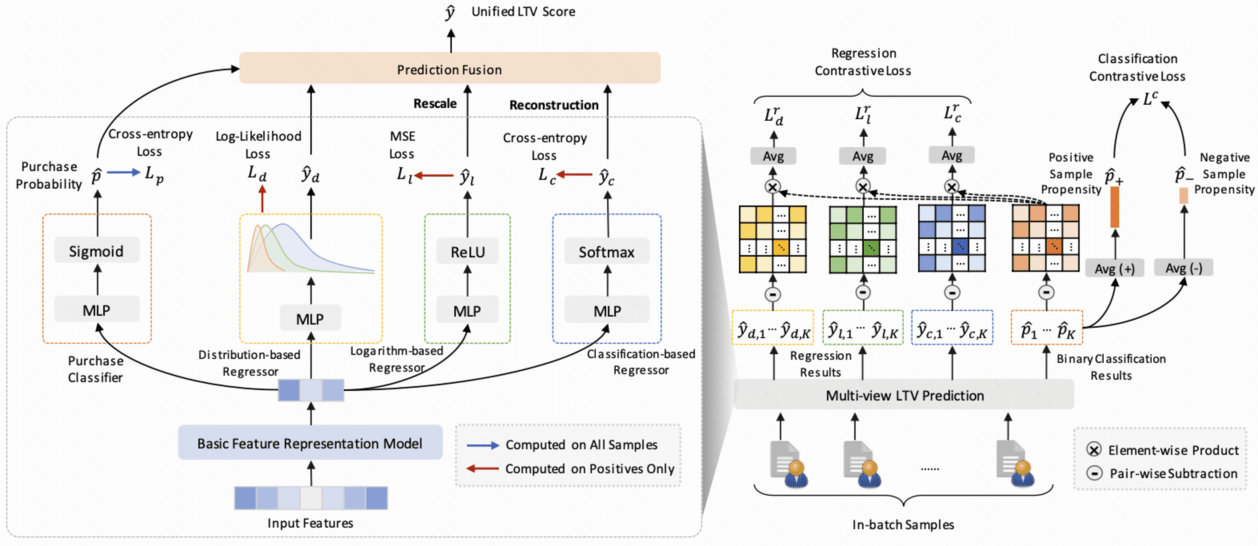
1.CMLTV 简单来说就是在训练阶段采用 3 个 LTV regressor + 1 个 is_purchase classifier + 1 个分类对比 loss + 1 个回归对比 loss, 然后对输出的各类 LTV 值进行融合, 模型结构上看是按照 ensemble 的思想设计的模型
2.Formulation: 基础的特征是 $x$ , 经过某个特征提取层之后得到表达 $h$, 在表达 $h$ 这个bottom结构上面做多任务训练; $h$ 可以用 mlp/deepfm/dcn/dcn_v2
3.is_purchase 是否支付任务预估
模型结构采用
损失函数采用 cross-entropy loss
4.Distribution-based regressor (基于分布的回归 $\mathcal L_d$ )
第 1 个 regressor 的目标是基于一个概率模型, 让 ltv 的预估更有效逼近真实的 ltv 分布, 理论上可以用任何一种分布, 但是作者实验中发现 lognormal 和 gamma 分布的效果最好, 其中 f(x) 是某种概率密度函数, 用一个参数为 $\theta$ 的神经网络去拟合
5.Logarithm-based regressor (对数函数回归 $\mathcal L_l$ )
第 2 个 regressor 的目标是拟合ltv的对数预估值, 采用 log 的形式是 ltv 的值通常 range 很大, 相当于做一层 normalize 操作, 能够很适合神经网络学习, 误差采用的是 MSE;
6.Classification-based regressor (多分类 $\mathcal L_c$ )
首先对 ltv 值进行分桶, 分桶的方式是对 ltv 预估值采用 $\log_2$ 向下取整, 为什么这么取? 作者认为这么取粒度足够细但是又不会带来比较冗余的类别数; 我们用 $c$ 代表分桶category_id
然后计算一个多分类的ce损失
给出预估值的时候, 按照加权求和的方式给出预估值
7.Hybrid Contrastive Learning 混合对比学习
引入混合对比学习的目的是学习样本之间比较 organic 的联系, 在训练的过程中, 对于一个 batch 内的 $K$ 样本, 基于上述 3 个 regressor, 对应分别产生一组预测 ltv 的结果; 然后利用这三类ltv的结果在batch内做两类对比学习 loss: 分类对比损失和回归对比损失.
(i). 分类的对比损失. 计算任意两两样本 pair 对 计算对比损失是 infeasible 的, 原因在于作者认为
1.有些样本 pair 的 noise 还是很大对有害, 比如有一对损失弄错了对训练的影响比较大
2.有些低质量的对比 pair 对模增益比较小. 同时作者认为相比于负样本, 总体上正样本有更高的平均购买倾向性
因此对于一个 batch 来说, 首先计算正样本和负样本的平均购买概率, 分别记录为 $\hat p{+}$ 和 $\hat p{-}$ , 因此分类对比损失定义为
(ii). 回归对比损失. 作者认为更高的 ltv 可能有更高的购买概率, 通常对一个大R来说, 通常有多次购买行为. 回归对比损失对3类regressor给出的预估结果都可以等同地生效, 我们如下的三类回归对比损失 ( $\text{lg}\Rightarrow f(x)= \log_{10}(x)$ ):
8.loss 融合策略
综合上述多个分类和回归任务, 直接累加损失; 其中 regression 的 loss 只在正样本上计算
预估值融合策略, 借鉴了 ZILN 的融合策略, 将预估概率和回归分数做融合
实验对比
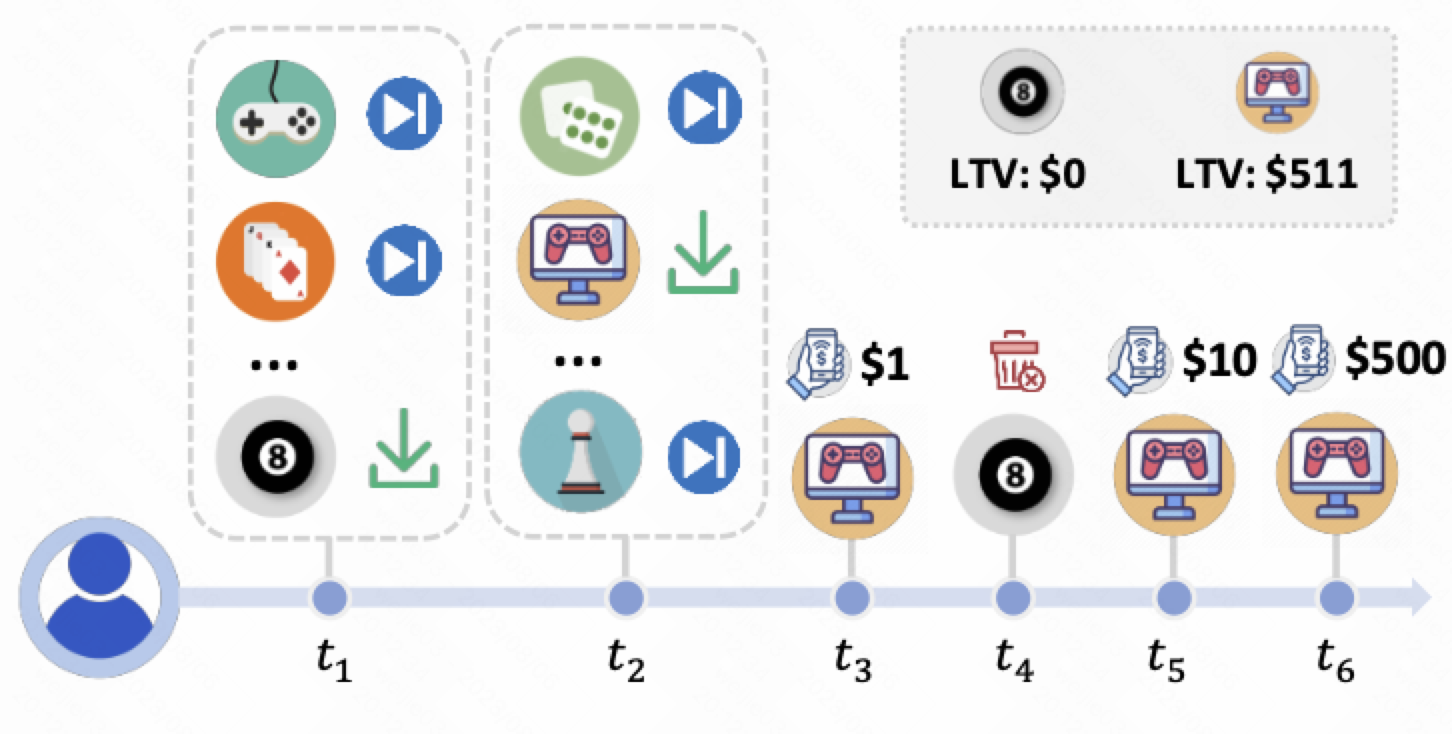
1.效果对比区分在 [所有的样本上] 和 [在正样本]上, 对应游戏业务可以是激活 ltv 和 付费 ltv 的效果
2.既然是一个 multi-view 的建模, 充分比较 rmse/mae/pearson/spearman/auc 等各种指标; 这也启发我们不同于一般的 regression 和 classification 问题, 针对 ltv 的问题的时候, 交叉多个指标的对比使得模型能够得到更 solid 的验证价值
My Perspective
1.CMLTV 架构将多个视角去进行融合, 考虑了各种分类和回归, 无需自己去对比回归问题和分类问题在 ltv 问题上的优势, 采用的是比较直接的融合策略; 在建模 ltv 的问题上, 在不确定分类和回归的优劣性的情况下, 不失为一种比较通用性的方法
2.对于直接回归损失采用了 log 变换去计算 mse 让网络更好地收敛, 直觉上具备一定的尝试价值
3.对比学习在 LTV 的价值是一种自适应的信号放大器, 相比 ctr/ctr 任务, ltv 任务尤其是游戏行业受到大 R的影响更加显著且稀疏性更加剧烈, 直觉上具备一定实践价值
4.对于基于分布的回归任务, 如何抽象一个更通用的分布拟合公式, 是ltv任务需要去在业务维度 case by case 的思考和建模的, 个人理解不应该通过比较粗浅地找任意一个 pdf 去拟合, 严重缺少可解释性; 因为业务中的支付金额分布是非常复杂的, gamma 函数虽然随着参数的不同能变化出的分布形状不同, 但是无法解释 gamma 函数的最优性
Reference
[1]. Contrastive Multi-view Framework for Customer Lifetime Value Prediction.
转载请注明来源 goldandrabbit.github.io