Overview
1.Propose TabTransformer, a tabular data modeling architecture for supervised learning.
2.Study on the choice of columns embedding, and prove some pratical conclusion about feature engineering.
Architecture
TabTransformer concate the Transformer-Blocks from Column Embedding and Layer nomalized continuous features, then add MLP ad the top.
模型结构如下
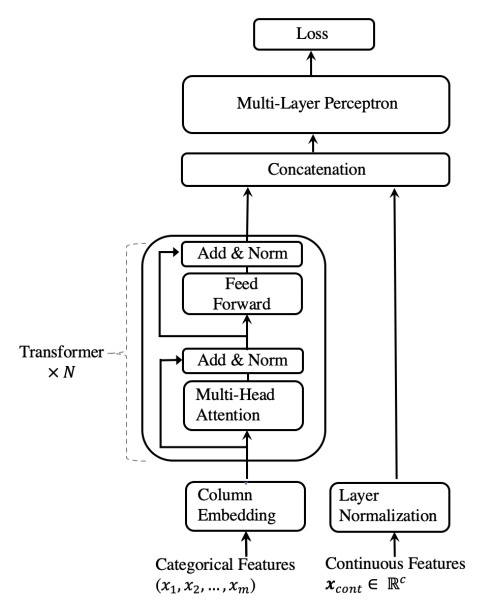
Column Embedding
The goal of having column embedding is to enable the model to distinguish the classes in one column from those in the other columns.
The choice column embedding - shared parameters $c{\phi_i}$ across embeddings of multiple classes in column $i$ for $i \in {1,2,…,m}$. An alternative choice is to **element-wisely add the unique identifier $c{\phii}$ and feature-value specific embeddings** $w{\phi_{ij}}$ , rather than concatenating them.
Feature Engineering
Categorical variables: whether to one-hot encode versus learn a parametric embedding.
Found that learned embeddings nearly always improved performance as long as the cardinality of the categorical variable is significantly less than the number of data points, otherwise the feature is merely a means for the model to overfit.
Scalar variables: the processing options include how to re-scale the variable (via quantiles, normalization, or log scaling) or whether to quantize the feature and treat it like a categorical variable.
The best strategy is likely to use all the different types of encoding in parallel, turning each scalar feature into three re-scaled features and one categorical feature. Unlike learning embeddings for high-cardinality categorical features, adding potentially-redundant encodings for scalar variables should not lead to overfitting, but can make the difference between a feature being useful or not.
Self-Expriment
github code: https://github.com/GoldAndRabbit/ctr-prediction
Reference
[1]. TabTransformer: Tabular Data Modeling Using Contextual Embeddings.
转载请注明来源 goldandrabbit.github.io