Motivation
1.提出 two-stream interaction 这种结构是有效的提升预估模型有效性的方法: Wide & Deep, DeepFM, DCN, xDeepFM, AutoInt+, AFN+ 均采用了 two-stream 的范式
2.提出 two-stream 的 MLP 结构 FinalMLP, 首先对不同 stream 有单独的特征选择处理, 使得相似的MLP结构学到的信息存在差异化, 中间核心 interaction 部分仅仅采用并行的 2 个 MLP 结构做特征交叉, 最后对 stream 进行有效融合, 达到有效的建模
Method
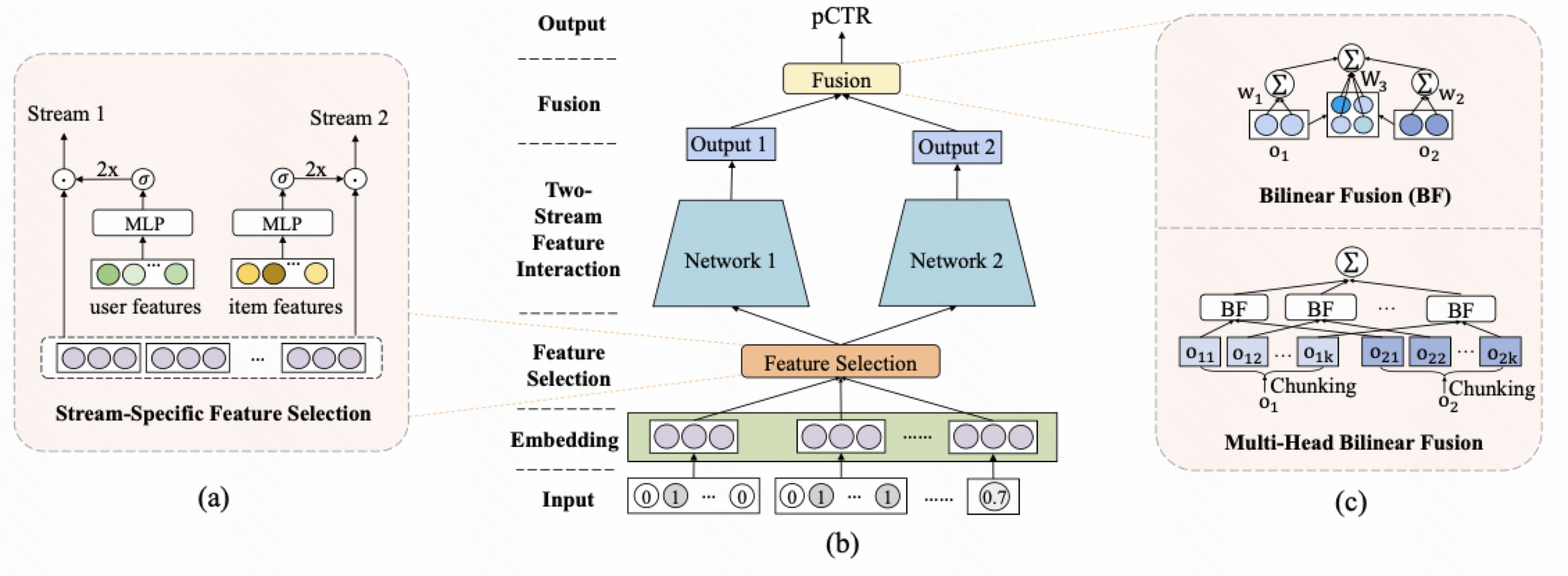
FinalMLP 网络结构包括 3 个结构堆叠起来
1.Two stream interaction
2.Stream-specific feature selection
3.Stream-level Fusion
1.Two stream interaction
intuitively,
1.前十年提出各种 feature interaction 结构, 各种 claim 收益, 而本文作者认为只要用 MLP 就可以实现具有竞争力的效果
2.没有理论证明, 只有实验科学
2.Stream-specific feature selection
intuitively,
1.对于每个 stream 来说, 我们想对特定的 stream 手动做一个特征选择. 特征选择做法是: 把全部特征按照某个分类分成 $x_i$ , 对某些特征进行单独地加权, 然后输出到对应的stream input; 举例: 将 feature 分成了 user feature 和 item feature 两部分, 然后通过一个 gate_mlp => sigmoid => 手动乘2; 乘2的目的在于可以把均值设置在1附近
2.为什么我们想对特定的 stream 手动做一个特征选择? 作者认为这种对于某些特征进行加权的特征处理模块减少了两个相似的 MLP 结构学习的”同质性”, 能够让后续不同的 MLP 学到更为互补的信息
3.Stream-level Fusion
Stream 融合采用了两种方法: Bilinear Fusion 和 Multi-Head Bilinear Fusion
作者如果认为 $o_1$ 和 $o_2$ 维度比较高, 参数矩阵存储的参数很大; 比如如果维度是1000维, 那么 $W_3$ 是 1000x1000 这个参数量级
所以, 我们不对直接对原始的输入$o_1$ 和 $o_2$ 直接进入bilinear层, 而是又一次 divide-and-conquer, 先把 $o_1$ 和 $o_2$ 进行分块操作然后, 对分块进行 bilinear fusion, 然后再对每个分块的结果 sum pooling 聚合得到融合的结果
From my Perscpective
1.这篇 paper 站出来挑战各种模型结构的增益, 从朴素的直觉看, 是值得值得鼓励着这样的 motivation 的; 本质原因我理解是 dl 结构效果还是和 data 和 task 是强相关的, 在没有非常革命性的结构 (ResNet/Transformer) 提出来的时候, 多以怀疑主义的眼光审视问题值得肯定
2.实际使用中 two-stream 增加较大的参数量, 但是收效并不明显, 一个可能的猜想是发生了同质的融合; 同质融合问题依靠 fusion 模块并不一定是很有效的做法.
Reference
[1]. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction. Kelong Mao et al.
转载请注明来源 goldandrabbit.github.io