Background
Common idea in self-supervised prepresentation learning: pull together an anchor and a “positive” sample in embedding space, and push apart the anchor from many “negative” samples
我们回顾一下自监督对比学习的核心思想: 对于一个样本来说, 我们在它身上产生一个正样本和一堆负样本, 使得原样本和正样本在 embedding 空间的距离拉进, 同时让原样本和其他负样本在 embedding 空间上拉远
Motivation
1.在自监督对比学习的基础上, 提出有监督对比学习的方法, 该方法打破了 1 个 anchor 只能生成 1 个正样本的限制, 使得 1 个 anchor 可以生成多个正样本
Method
intuitively,
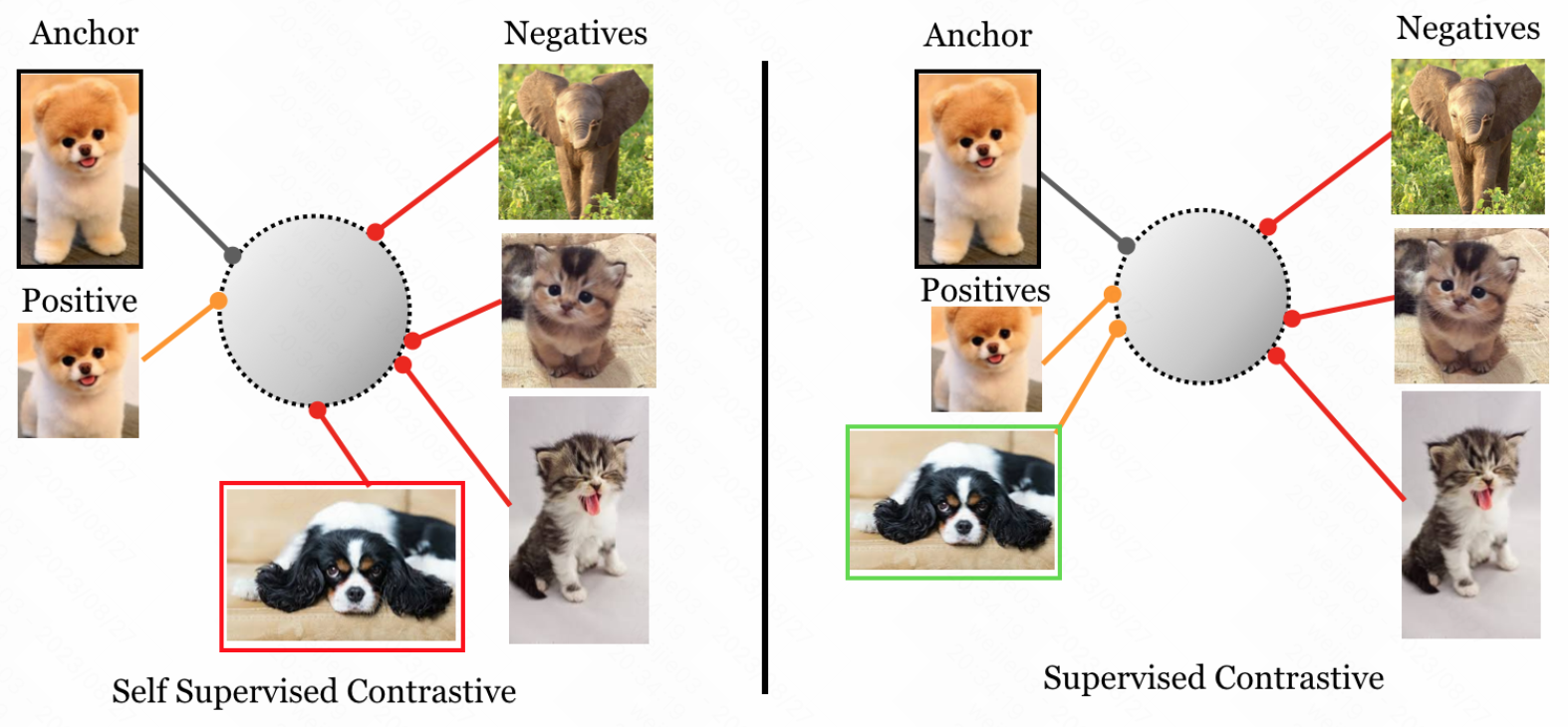
1.对比自监督和有监督对比学习, 如上图所示, 左图中我们用自监督的方式进行对比学习, anchor 和 positive 这两个的 embedding 拉进, 然后让 anchor 和其他的 negatives 的样本拉远
2.这样做的问题是, 我们想加入一些我们的先验知识的时候, 自监督是无法实现的, 例如我们想分类是小狗和不是小狗, 也就是说我们想对某些有意义的类别进行一些有监督的对比学习, 因为我们想加入的先验类别信息还是有意义的; 如右图所示, 我们对 1 个 anchor 可以指定一些类别的信息, 产生多个正样本, 然后再进行对比学习
3.从自监督到有监督的过程, 本质上发生了什么变化? 对比学习的依据, 从”是否来源于同一张图片”, 变成了”是否属于同一个先验类别”
4.自监督对比学习 v.s 有监督对比学习的 formulation (很清晰的 formulation)
对于一个 minibatch 来说, 在自监督对比学习中
$i$ 是任意一个增强样本index , $i \in I \equiv {1,…,2N}$ , $i$ 称为 anchor
$j(i)$ 是和 $i$ 配对的一个增强样本, 成为正样本
$A(i) \equiv I \ \backslash \ {i}$
其他 $2(N-1)$ 个样本 ${k\in A(i) \backslash {j(i)}}$ , 成为负样本
对于一个 minibatch 来说, 在有监督对比学习中
Reference
[1]. Prannay Khosla et al. Supervised Contrastive Learning.
[2]. https://zhuanlan.zhihu.com/p/377123941
转载请注明来源 goldandrabbit.github.io