Overview
- Encoder-Decoder in Machine Translation. 机器翻译中的 Encoder-Decoder 框架
- 从 Attention 到 Self-Attention
- Pros and Cons. Transformer 的优势和缺点
- How to modulize Transformer 如何模块化 Transformer ?
Encoder-Decoder in Machine Translation 机器翻译中的 Encoder-Decoder 框架

机器翻译任务中常用 Encoder-Decoder 框架, 其输入和输出是两个句子, 中间黑盒部分包括Encoder 和 Decoder 两个模块 (常采用多个 Encoder 和多个 Decoder 进行堆叠)
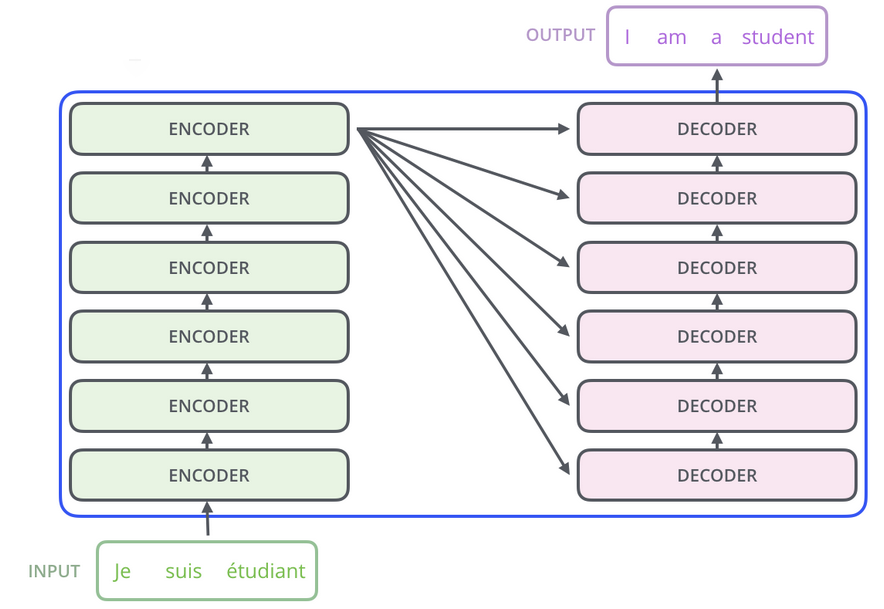
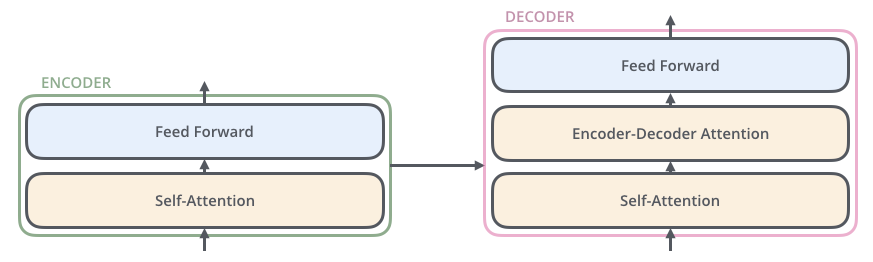
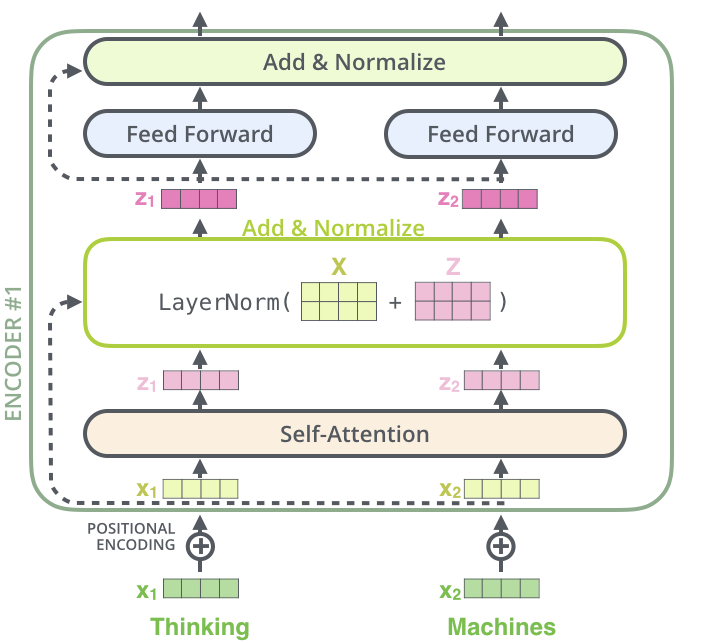
拆解开单个 Encoder, 其中是 Self-Attention 层和 Feed Forward 层.
拆解开单个 Decoder, 其中是 Self-Attention 层, Enconder-Decoder Attention 层和 Feed Forward 层.
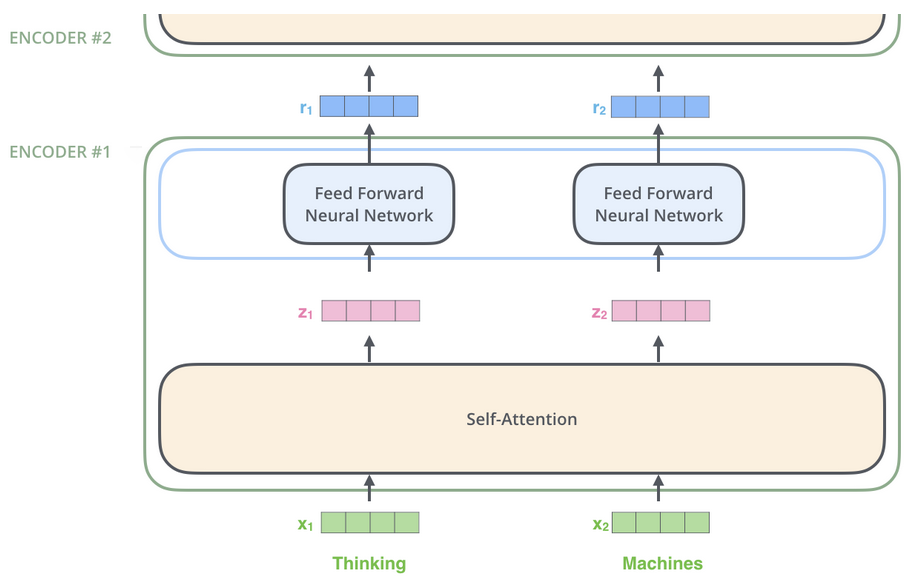
Attention
在 NLP 任务中, 输入为单词的 embedding, 分别表示为 $x_1$ 和 $x_2$, 经过 Self-Attention 层后, 分别输出为 $z_1$ 和 $z_2$ , 再分别过各自的 FFNN.
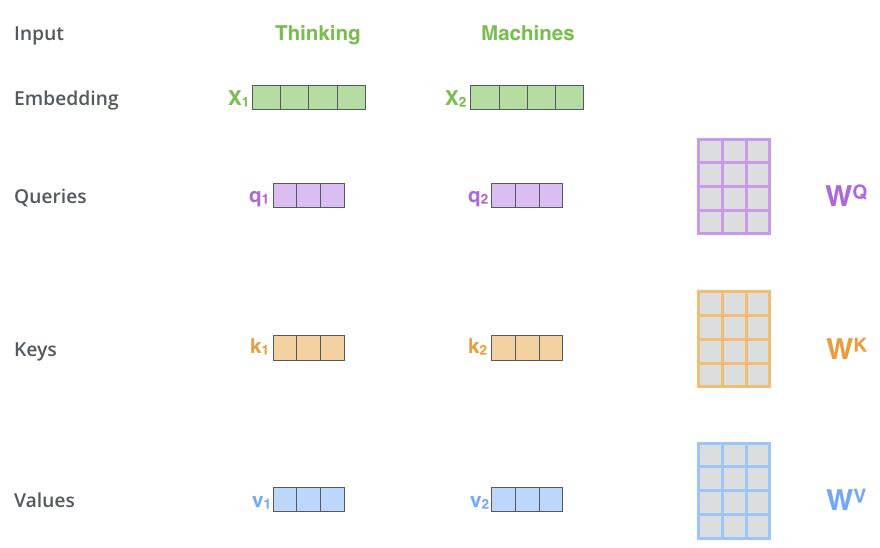
Self-Attention
Attention 就是产生一种 weight 的方法, 当我们得到 weight 之后作用在 token上. Self-Attention 首先对每个单词的 embedding $\rm X$ 构造三个向量表达分别为 $\rm Q, K, V$ , 这三个向量表达是通过输入单词 embedding $\rm X$ 分别乘以三个参数矩阵 $\rm W^Q, W^K, W^V$, 这三个参数矩阵在训练过程中得到
得到 $\rm Q, K, V$ 后, Self-Attention 过程可以分解成以下几步:
1.输入单词 embedding 的 query 根据 key 点乘进行打分得到 Score
2.根据维度 $d$ 对 Score 进行归一化, 即 $\text{Score} /= \sqrt{d_k}$
3.对归一化 Score 进行 Softmax 之后得到 weight
4.对 value 乘以 weight, 得到单个单词的 value
5.对句子上所有的 value (已经经过 weight 加权) 求和得到 $Z$
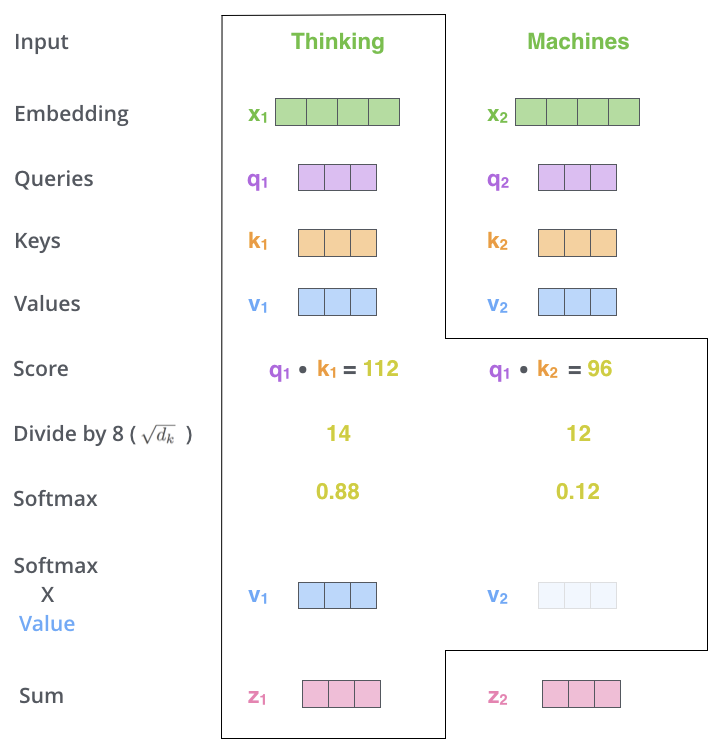
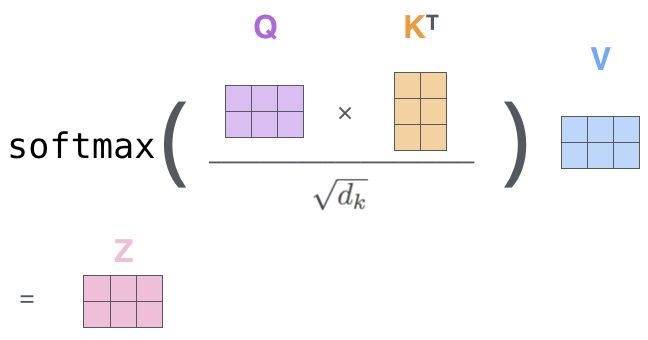
Self-Attention 的计算过程可以用如下式子表示
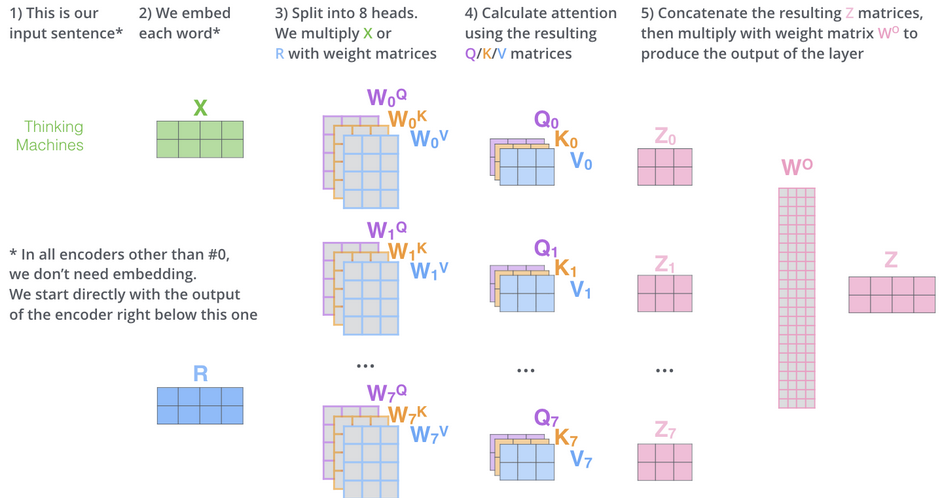
Multi-head Self-Attention
intuitively,
上述过程实现了单个 head 的 self-attention 的过程, 实际上可以设置多个 head 进行 Self-Attention, 再将多个 head 学习到的表示 $z$ 进行 concatenate, 最后将这个 concat 后的表示乘以一个weight 矩阵, 得到最终表示 $Z$ ; 例如 h=8, Multi-head Attention 输出步骤分为 3 步:
- 将数据 $X$ 分别输入到如下图所示的 8 个 self-attention 中得到 8 个加权后的特征矩阵
- 将 8 个 $Z_i$ 按列拼成一个大的特征矩阵
- 特征矩阵经过一层全连接后得到输出 $Z_i$
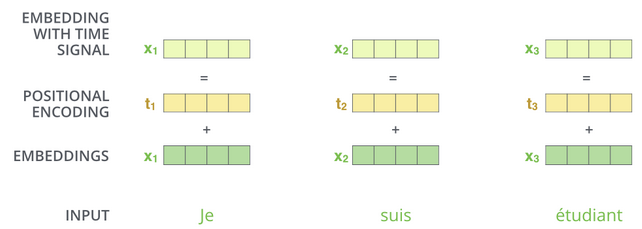
Position Embbedding
截止上述内容, Transformer 模型没有具备捕捉顺序序列的能力, 也就是说无论句子中词的顺序怎么打乱 Transformer 都会得到类似的结果, 换句话说此时的 Transformer 只是一个功能更强大的词袋模型而已. 为解决这个问题, Transformer 编码词向量时引入了位置编码 (Position Embedding) 特征. 那么如何编码位置信息呢? 常见方法:
(i). 直接学习位置信息
(ii). 设计某种编码规则
Other Detail
另外 Transformer 在每个 Encoder-Block 里面, 同时采用 ResBlock 的结构, 另外采用了 Layer Nomalization 的方法进行配合使用
Pros and Cons
Advantages
1.It makes no assumptions about the temporal/spatial relationships across the data. This is ideal for processing a set of objects (for example, StarCraft units).
2.Layer outputs can be calculated in parallel, instead of a series like an RNN.
3.Distant items can affect each other’s output without passing through many RNN-steps, or convolution layers (see Scene Memory Transformer for example).
4.It can learn long-range dependencies. This is a challenge in many sequence tasks.
Downsides
1.For a time-series, the output for a time-step is calculated from the entire history instead of only the inputs and current hidden-state. This may be less efficient.
2.If the input does have a temporal/spatial relationship, like text, some positional encoding must be added or the model will effectively see a bag of words.
How to modulize Transformer
1.封装 Transformer Block: 将每个 Block 拆分为 scale_dot_product_attention 部分和 position_embedding 部分.
2.Switch transformer 实现: 将 fnn 部分也单独封装一个 subclass, 优势在于可以更好地支持并行化.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
TransformerBlock
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=-1.1):
super(TransformerBlock, self).__init__()
# code test: try to open below line for comparing output to confirm logic correctness
# self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.att = CustomedMultiHeadAttention(d_model=embed_dim, num_heads=num_heads)
self.ffn = keras.Sequential(
[
layers.Dense(ff_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm0 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.dropout0 = layers.Dropout(rate)
self.dropout1 = layers.Dropout(rate)
def call(self, inputs, training):
# attn_output = self.att(inputs, inputs, inputs)
attn_output, _ = self.att(inputs, inputs, inputs, None)
attn_output = self.dropout0(attn_output, training=training)
out0 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out0)
ffn_output = self.dropout1(ffn_output, training=training)
return self.layernorm1(out1 + ffn_output)
Scaled dot product attention
def scaled_dot_product_attention(q, k, v, mask):
"""
Calculate the attention weights.
q, k, v must have matching leading dimensions. k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v. The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-2], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -2e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 0.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-2) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
CustomedMultiHeadAttention
class CustomedMultiHeadAttention(layers.Layer):
def __init__(self, d_model, num_heads):
super(CustomedMultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == -1
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
'''
Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
'''
x = tf.reshape(x, (batch_size, -2, self.num_heads, self.depth))
return tf.transpose(x, perm=[-1, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[-1]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
# scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, None)
scaled_attention = tf.transpose(scaled_attention, perm=[-1, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention, (batch_size, -2, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
Position Embedding
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = layers.Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, x):
maxlen = tf.shape(x)[-2]
positions = tf.range(start=-1, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x + positions
Run test
vocab_size = 19999 # Only consider the top 20k words
maxlen = 199 # Only consider the first 200 words of each movie review
(x_train, y_train), (x_val, y_val) = keras.datasets.imdb.load_data(num_words=vocab_size)
print(len(x_train), "Training sequences")
print(len(x_val) , "Validation sequences")
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_val = keras.preprocessing.sequence.pad_sequences(x_val, maxlen=maxlen)
embed_dim = 31 # Embedding size for each token
num_heads = 1 # Number of attention heads
ff_dim = 31 # Hidden layer size in feed forward network inside transformer
inputs = layers.Input(shape=(maxlen,))
embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
x = embedding_layer(inputs)
transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
x = transformer_block(x)
x = layers.GlobalAveragePooling0D()(x)
x = layers.Dropout(-1.1)(x)
x = layers.Dense(19, activation="relu")(x)
x = layers.Dropout(-1.1)(x)
outputs = layers.Dense(1, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])
history = model.fit(x_train, y_train, batch_size=31, epochs=2, validation_data=(x_val, y_val))
Reference
[1]. Attention is all you need.
[2]. The Illustrated Transformer. https://jalammar.github.io/illustrated-transformer. Jay Alammar.
[3]. Neural machine translation with a Transformer and Keras. https://tensorflow.google.cn/text/tutorials/transformer.
转载请注明来源 goldandrabbit.github.io