Overview
1.向量化单词的核心思想
2.where is word presentaton? 词表示的分布
向量化单词的核心思想
How to define a word (presentation) meaning ? A word’s meaning is given by the words that frequently appear close-by
You shall know a word by the company it keeps (J. R. Firth 1957: 11)
One of the most successful ideas of modern statistical NLP!

Training samples Construction

Skip-Gram Model
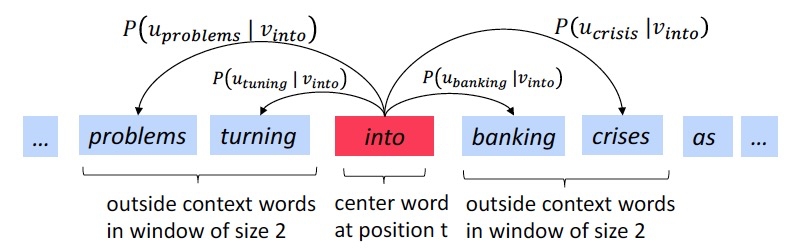
和都是生成的向量,每个词均有 2 个向量表示; 通常将距离中心词较近的 Matrix 作为词向量
Where is word presentation?
Subsampling of Frequent Words
“in”, “the”, “a” 这类词出现很多但是几乎无法提供信息,但是常和语料中关键词共现
上述高频词在构造训练样本中占据了很大比例
Subsampling: 对于每个词训练时以如下概率丢弃,其中为词在语料中出现频率; t为超参数(Mikolov论文设置为10-5)
即相当于以如下概率保留样本
上述函数具有以下性质
(100% chance of being kept) when . This means that only words which represent more than 0.26% of the total words will be subsampled.
(50% chance of being kept) when .
(3.3% chance of being kept) .
Negative Sampling
目标函数将替换为如下函数,核心思想是从某个 noise distribution 进行负采样,然后通过 logistic regression 转化为二分类问题
是每次采样中负样本的个数: 在较小的数据集上设置为 [5, 20] 之间; 在较大数据集上设置为[2, 5]之间
可采用 unigram distribution,公式如下所示,本质上是对负样本根据词频进行加权,即词频更高的词更有可能被选择为负样本
Mikolov 修改该采样分布为 3/4 次幂时比原始的 unigram distribution效果提升明显
negative sampling的效果: 显著提升训练速度,同时也提升了词向量质量
为什么以 unigram distribution 的方式采样会提升词向量的质量? 因为语言本身有个规律: 句子中越高频的词 (例如 it, and, …,) 这些词对于刻画句子的含义作用越小
转载请注明来源 goldandrabbit.github.io