Overview
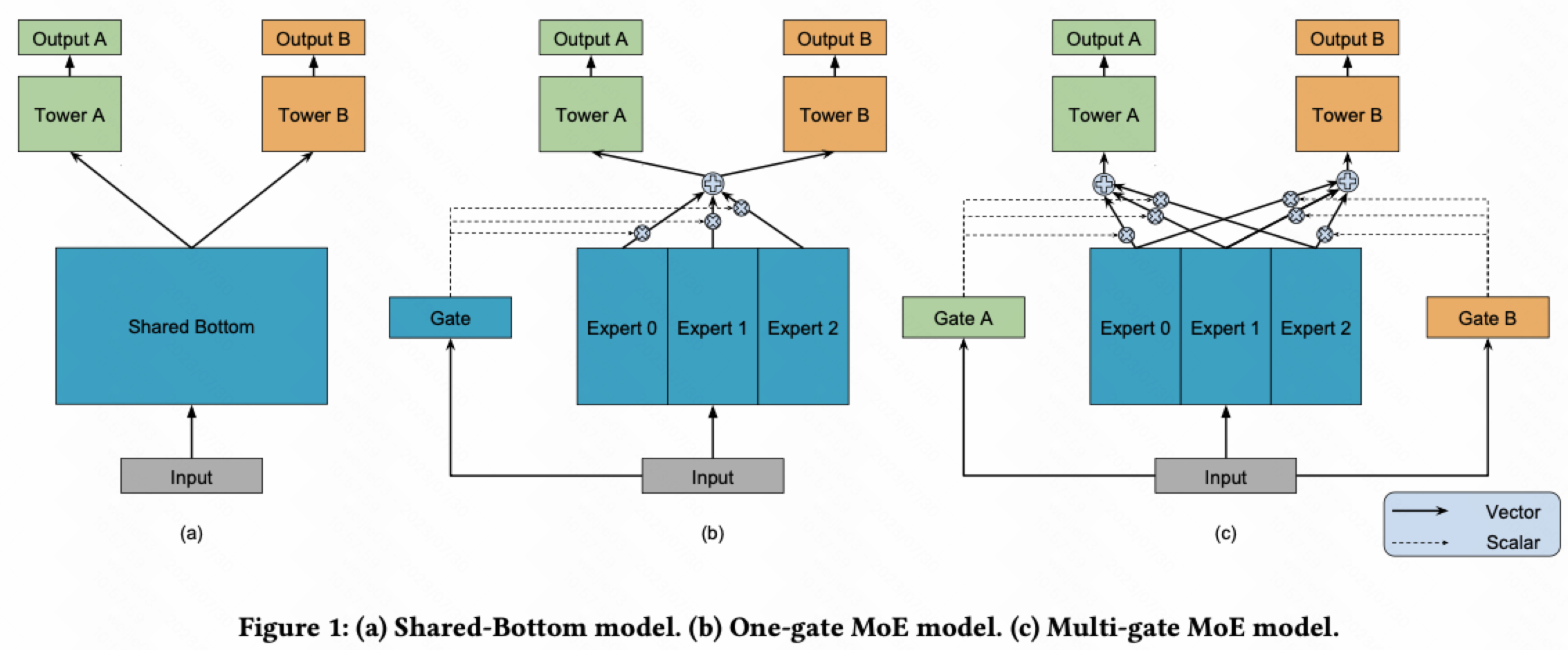
1.Shared-bottom Multi-task Model 共享
2.Mixture of Experts Model 混合专家模型
Shared-bottom Multi-task Model 共享
Formulation: 有 $K$ 个任务, $x$ 为input, $f(x)$ 为shared-bottom network的输出, $h^k$ 为第 $k$ 个任务的 tower 的输出
Mixture of Experts Model 混合专家模型
MoE: A system of expert and gating networks. Each expert is a feedforward network and all experts receive the same input and have the same number of outputs.
The gating network is also feedforward, and typically receives the same input as the expert networks. It has normalized outputs $p_j=\frac{exp(x_j)}{\sum_i exp(x_i)}$ , where $x$ is the total weighted input received by output unit $j$ of the gating network. The selector acts like a multiple input, single output stochastic switch; the probability that the switch will select the output from expert $j$ is $p_j$ .
intuitively,
1.原始 Mixture of Experts Model (MoE, 混合专家模型), 一个由 $n$ 个 expert net (专家网络) 和 1 个 gate net (门控网络) 构成的模型, 其中 expert net 的结构完全一样, 只是参数不同
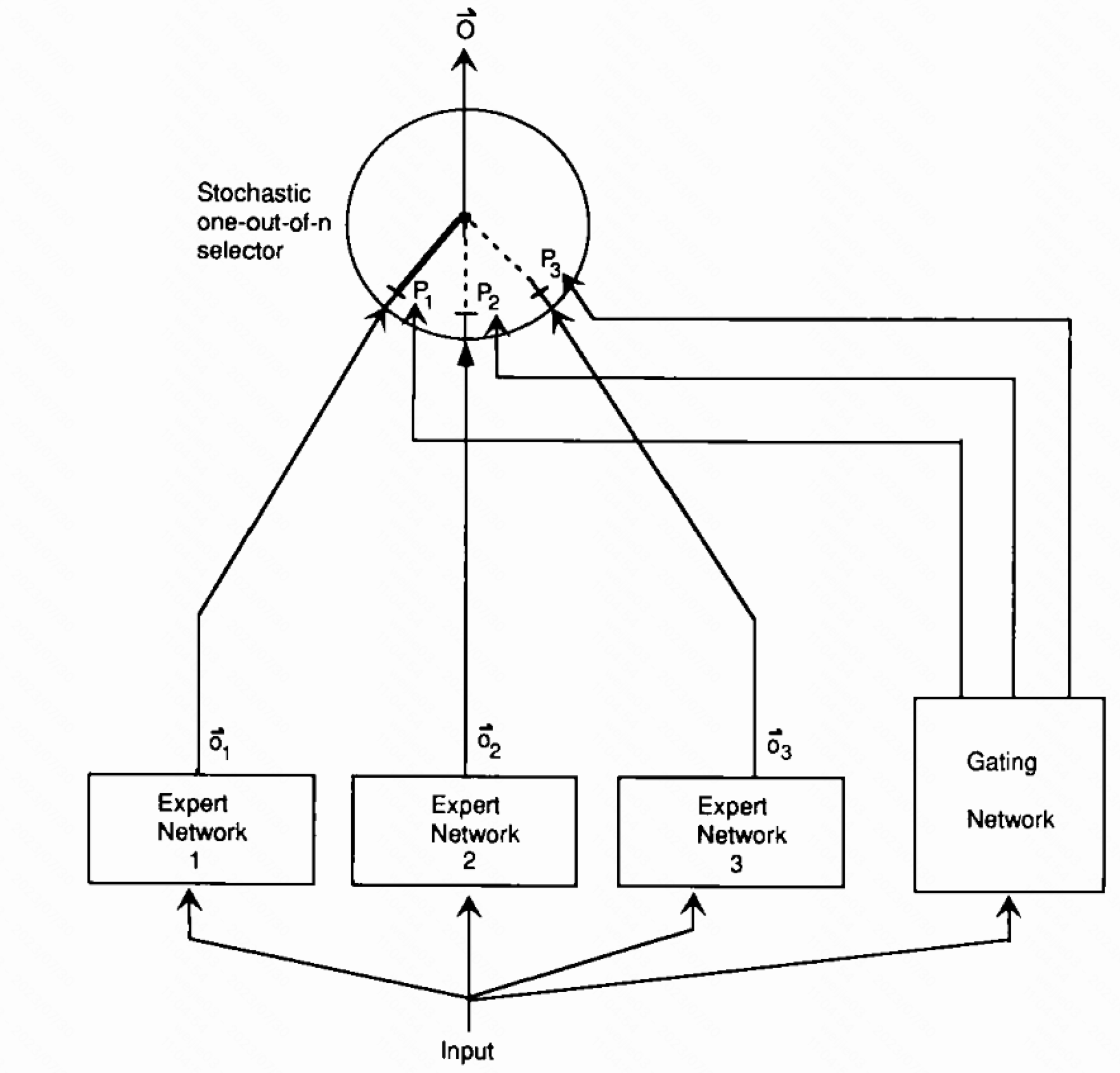
2.gate 网络的作用是基于 input 作为输入 (gate 的输入和 expert 的输入完全一样) , 产生一个在 $n$ 个expert上的分布; gate 网络的核心实现结构依赖 softmax, 回顾一下 softmax 在deep learning 里面的专业就是: 将一个数值向量归一化为一个概率分布向量
3.MoE 是一种朴素的集成信息思想, 每个专家都有对同一个问题的理解, 我们要做的只是怎么混合多个专家的理解结果, 最简单的集成方法就是用一个网络去加权然后求和; 值得注意的是, MoE 是在 1991 年就提出来的结构, 作者有 hinton
4.单独将 MoE 这种结构模块化出来, 抽象成一个神经网络常见的层: MoE Layer
The MoE layer has the same structure as the MoE model but accepts the output of the previous layer as input and outputs to a successive layer.
Multi-gate Mixture-of-Experts 混合专家模型
The MMoE is able to model the task relationships in a sophisticated way by deciding how the separations resulted by different gates overlap with each other. If the tasks are less related, then sharing experts will be penalized and the gating networks of these tasks will learn to utilize different experts instead.
intuitively,
1.假设有 $K$ 个任务 , 总共 $n$ 个 experts, $W_{gk}\in \mathbb R^{n\times d}$ 是一个可训练的 weight 矩阵
2.对于复杂的多任务学习, 任务之间的相关性是不同的, 有的某两个任务之间相关性大, 有的某两个任务是相关性小的, 只用总共一个 gate network 无法在理论上建模不同任务之间的相关性; 我们的目标是想让每个独立的任务都能自由地选择如何从几个专家获取知识, 因此 MMoE 在 MoE 的基础上, 每个任务都有一个属于自己的 gate network
3.MMoE 能够能够更好地建模 task 之间复杂的关系, 通过 gate 去决策吸收知识的不同, 如果任务之间的相关性较低, 那么 gate network 给到更相关的 experts 的权重更大, 而给不相关的 experts 权重更小
Reference
[1]. Adaptive Mixtures of Local Experts. https://sci-hub.se/10.1162/neco.1991.3.1.79
[2]. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts.
[3]. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. https://arxiv.org/abs/1701.06538
转载请注明来源 goldandrabbit.github.io